
Un score peut-il valoir une promesse ?
Il existe, depuis peu, un outil qui prétend résoudre un problème que personne n’avait encore posé assez clairement : comment comparer des robots IA entre eux, lorsque chaque laboratoire publie ses propres épreuves, ses propres critères, et — il faut le dire sans détour — ses propres intérêts ? L’Allen Institute for AI a mis en ligne vla-evaluation-harness : un cadre d’évaluation unifié conçu pour les modèles dits VLA — Vision-Language-Action, c’est-à-dire des IA capables de voir leur environnement, de comprendre des instructions en langage naturel et de générer des actions motrices en réponse. Ce framework rassemble huit environnements de test distincts (parmi lesquels SimplerEnv, CALVIN ou LIBERO), distribués sous forme d’images Docker — des conteneurs logiciels qui garantissent que les conditions d’essai sont rigoureusement identiques d’un laboratoire à l’autre, quel que soit le pays où tourne la machine — et placés sous licence Apache 2.0, c’est-à-dire librement utilisables, modifiables et redistribuables par quiconque en fait la demande. Voilà pour les faits.
Mais la question que soulève cet outil n’est pas technique. Elle est d’ordre conceptuel, et l’on commettrait une erreur en l’esquivant : que signifie mesurer les capacités d’un robot ? Et surtout — c’est là que tout se joue, et que le débat sur la standardisation devient réellement intéressant — qui décide qu’un score est suffisant pour autoriser le déploiement d’une machine dans un environnement réel ?
Cette question devrait précéder tout débat sur les étalons de mesure, non le conclure. Car c’est elle qui structure les désaccords, révèle les présupposés, et situe le vrai lieu du problème.
La première posture est celle de l’optimiste, et elle n’est pas sans arguments. Dans la situation actuelle, chaque constructeur publie ses propres métriques sur ses propres scénarios — ce qui revient, pour reprendre une analogie familière, à laisser chaque candidat à un concours rédiger lui-même les questions de son examen et corriger sa propre copie. Un étalon commun, même imparfait, même provisoire, constitue d’abord un outil de lisibilité : il permet de comparer ce qui, jusqu’ici, ne pouvait pas l’être. Et la licence ouverte d’vla-evaluation-harness n’est pas un détail — elle signifie que les laboratoires disposant de moyens modestes peuvent participer à l’évaluation sur un pied d’égalité, au lieu de subir des étalons taillés par et pour les plus grands acteurs du secteur.
L’histoire des sciences offre d’autres exemples de ce mouvement : les premières tentatives de standardisation des mesures de temps au XVIIe siècle, ou l’adoption progressive du système métrique au XVIIIe, ont toujours suscité des résistances — précisément parce qu’elles redistribuaient un pouvoir que certains détenaient précisément par l’opacité des unités locales. Un étalon commun est, en ce sens, un acte politique autant qu’un acte technique.
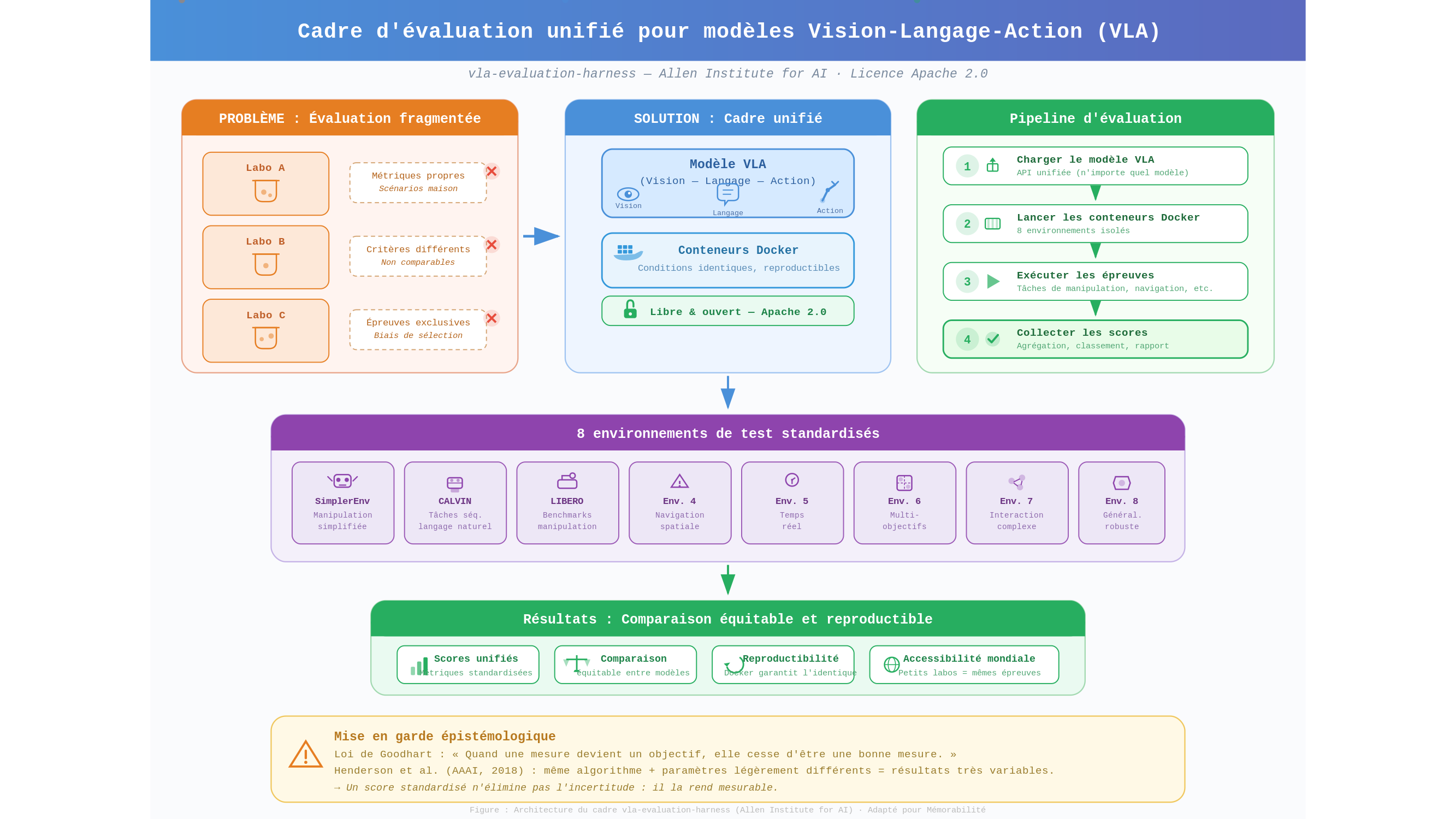
La deuxième posture reconnaît la force de cet argument, mais pointe une difficulté que l’histoire, justement, a également documentée. En 2018, Peter Henderson et ses collègues publiaient à la conférence AAAI — l’une des principales réunions mondiales sur l’apprentissage automatique — un article dont le titre portait déjà son propre diagnostic : « Deep Reinforcement Learning That Matters » — que l’on pourrait traduire par « apprentissage par renforcement profond qui compte vraiment ». Leur démonstration était sobre et dérangeante : les mêmes algorithmes, entraînés sur les mêmes environnements mais avec des paramètres légèrement différents ou des séquences aléatoires distinctes, produisaient des résultats qui variaient de façon considérable — au point de rendre les comparaisons entre systèmes concurrents non seulement fragiles, mais potentiellement trompeuses.
Ce phénomène est une illustration de ce que l’économiste Charles Goodhart avait formulé dès les années 1970 : « quand une mesure devient un objectif, elle cesse d’être une bonne mesure. » Un robot entraîné à maximiser un score sur huit référentiels d’évaluation standardisés apprend à maximiser ce score — ce qui n’est pas nécessairement la même chose qu’apprendre à agir de façon fiable dans un monde qui, lui, ne connaît pas les règles du banc d’essai.
Que se passe-t-il alors lorsqu’une machine obtenant d’excellents résultats en simulation se trouve confrontée à une situation imprévue — un objet déplacé, un sol mouillé, un utilisateur qui ne réagit pas comme prévu ? Prenons le cas, à titre illustratif, d’un robot déployé dans un environnement de soin : un score de simulation ne saurait constituer une assurance. Ce n’est pas une faille technique qu’il suffirait de corriger — c’est une promesse de sécurité qui repose sur une confusion entre la carte et le territoire.
La troisième posture déplace le regard, et c’est peut-être elle qui pose la question la plus difficile à esquiver. Admettons qu’un étalon commun soit utile, admettons même qu’il soit robuste : il reste qu’un standard technique sans seuil éthique associé fonctionne comme un permis de construire sans normes parasismiques. Il certifie une performance dans des conditions données ; il ne dit rien sur les conditions dans lesquelles cette performance est acceptable.
En 2026, les cadres de régulation existants — l’AI Act européen, les travaux de l’ISO/TC 299 sur la robotique — demeurent lacunaires sur le rythme d’adoption dans les environnements sensibles. Les huit référentiels d’vla-evaluation-harness mesurent ce qu’un robot sait faire dans un simulateur. Ils ne mesurent pas ce qu’il est légitime de lui demander de faire, ni qui porte la responsabilité lorsque la réponse est insuffisante. La gouvernance de ce seuil — cette ligne en deçà de laquelle on ne déploie pas, au-delà de laquelle on autorise — ne peut pas être confiée aux mêmes acteurs qui conçoivent les systèmes et bénéficient de leur diffusion. Cela n’est pas une question d’intentions : c’est une question de structure. Un juge ne peut pas être partie au procès.
Voilà donc le point de convergence des trois postures : elles s’accordent, au fond, sur le fait qu’un étalon universel co-construit, révisé périodiquement, et librement accessible vaut mieux que l’opacité actuelle. Là où elles divergent — irréductiblement —, c’est sur ce que cet étalon est censé garantir. Une performance ? Une sécurité ? Un droit au déploiement ?
La standardisation technique a ceci de séduisant qu’elle transforme des questions politiques en questions d’ingénierie : au lieu de demander « à qui appartient la décision ? », elle demande « quel seuil faut-il atteindre ? ». Mais le seuil ne répond pas à la question — il la dissimule.
Qui, alors, trace cette ligne ? Sur la base de quelles valeurs, de quelle représentation du risque, et au nom de qui ? Les référentiels d’évaluation répondent à beaucoup de questions utiles. Celle-là reste entière.
À lire aussi sur Émergence :
- FASTER : des robots qui réagissent en temps réel grâce à la vision et au langage
Sources
- Allen Institute for AI. vla-evaluation-harness — framework unifié d’évaluation de modèles VLA. GitHub, 2026. github.com/allenai/vla-evaluation-harness
- Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., & Meger, D. (2018). Deep Reinforcement Learning That Matters. Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32. [Conférence AAAI 2018, documentée et citable]