
1/ 🔭 Quarante-cinq ans. C’est le temps qu’un simple graphique à deux axes a régné sans partage sur la classification des galaxies. À gauche, celles qui fabriquent des étoiles. À droite, celles dont le cœur abrite un trou noir en plein festin. Entre les deux, une frontière tracée en 1981 par Baldwin, Phillips et Terlevich — trois noms devenus un acronyme : BPT. Aujourd’hui, cette frontière vacille.
2/ Le principe tient sur une serviette de café : mesurer deux rapports de raies lumineuses dans le spectre d’une galaxie. Selon ce qui ionise le gaz — des étoiles jeunes et chaudes, ou le rayonnement féroce d’un noyau actif —, les rapports basculent, et la galaxie atterrit d’un côté ou de l’autre du diagramme. Élégant. Efficace. Mais conçu pour quelques centaines de spectres.
3/ Or le relevé SDSS en contient déjà trois millions. Les catalogues à venir — DESI, 4MOST — en promettent dix fois plus. Imaginez un bibliothécaire qui trierait chaque livre en le lisant intégralement : à un moment, la bibliothèque grandit plus vite que ses yeux.
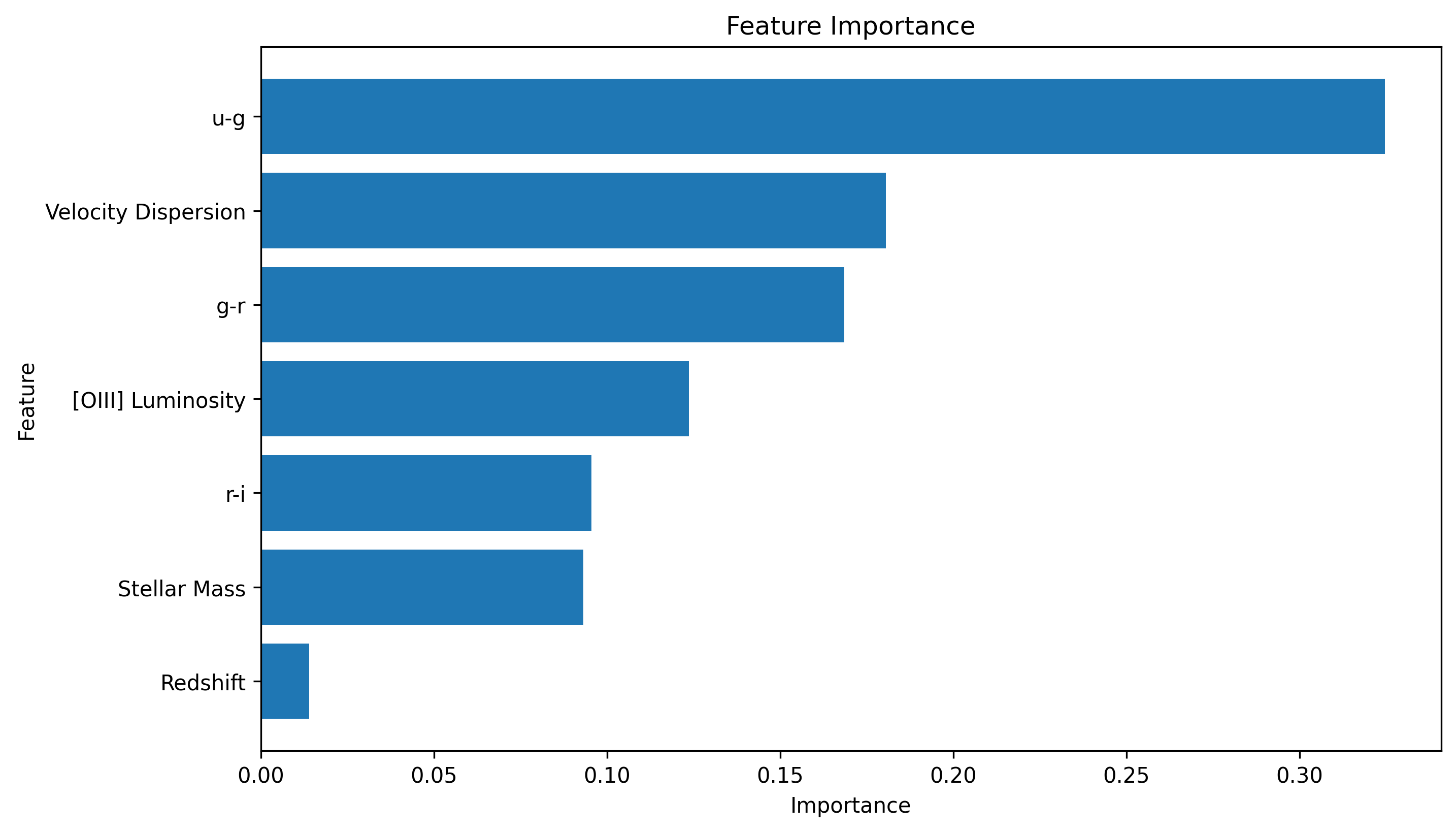
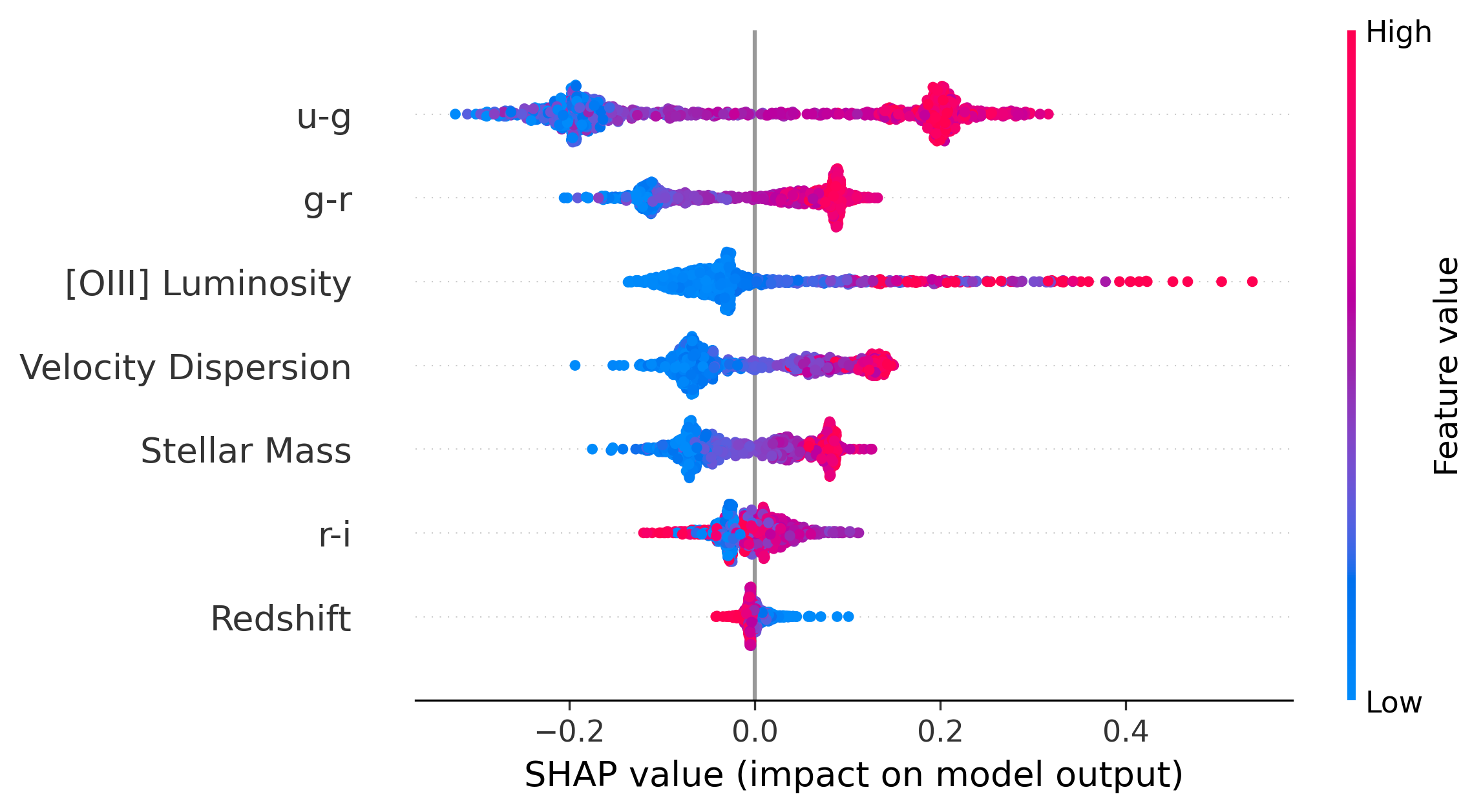
4/ C’est précisément le pari qu’a tenté l’équipe de Mazoochi, entre Téhéran et Bonn : remplacer la lecture du spectre par une poignée d’indices — masse stellaire, dispersion de vitesse, couleur, décalage vers le rouge, luminosité en [OIII] — et confier aux algorithmes d’apprentissage automatique (machine learning) la sélection du classement.
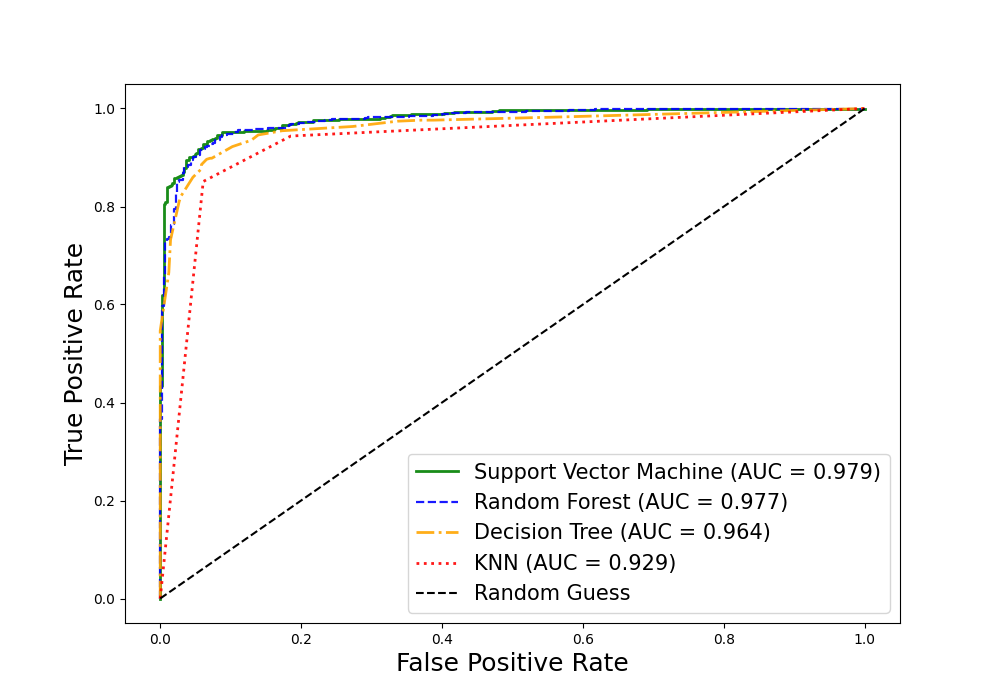
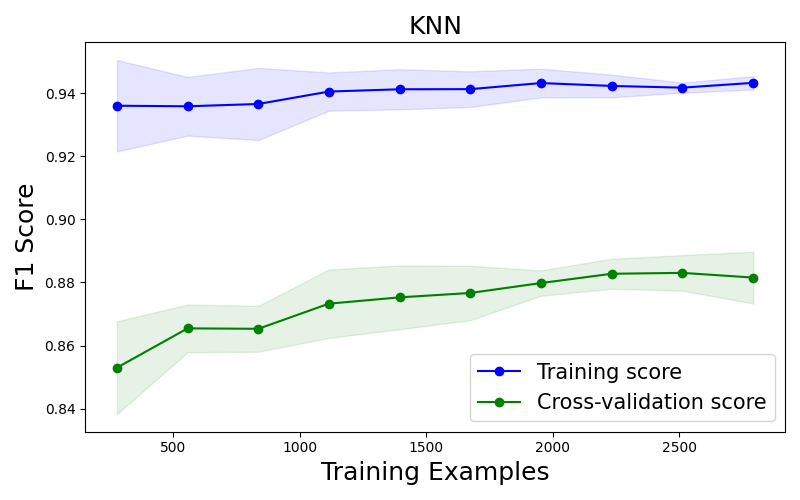
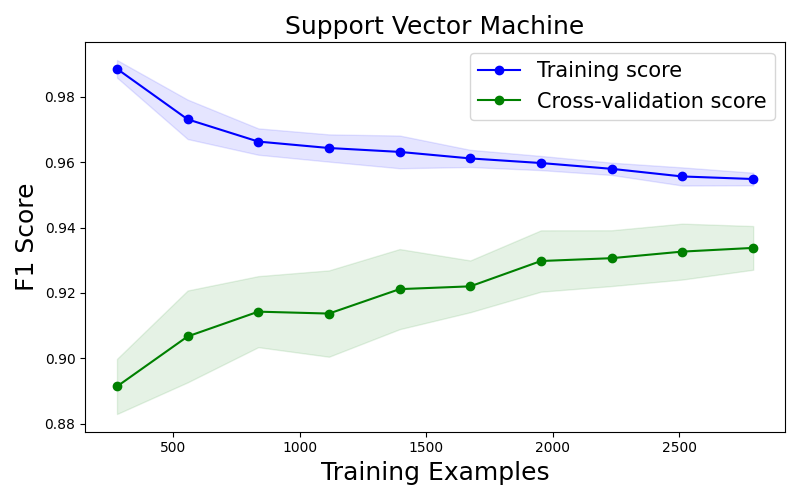
5/ Quatre méthodes testées sur 47 675 galaxies issues du projet Galaxy Zoo : machines à vecteurs de support, forêts aléatoires, k plus proches voisins, arbres de décision. Les deux premières retournent ~93 % de classifications correctes — le BPT reste l’étalon, mais les algorithmes lui marchent sur les talons sans jamais ouvrir un spectre. Nuance importante : le jeu de données est fortement déséquilibré (17 002 galaxies formatrices d’étoiles pour seulement 2 254 noyaux actifs) — un classifieur naïf qui ignorerait tout contexte atteindrait déjà ~88 % en pariant toujours sur la même catégorie. Le gain réel est réel, mais il faut le mesurer à l’aune de cette base.
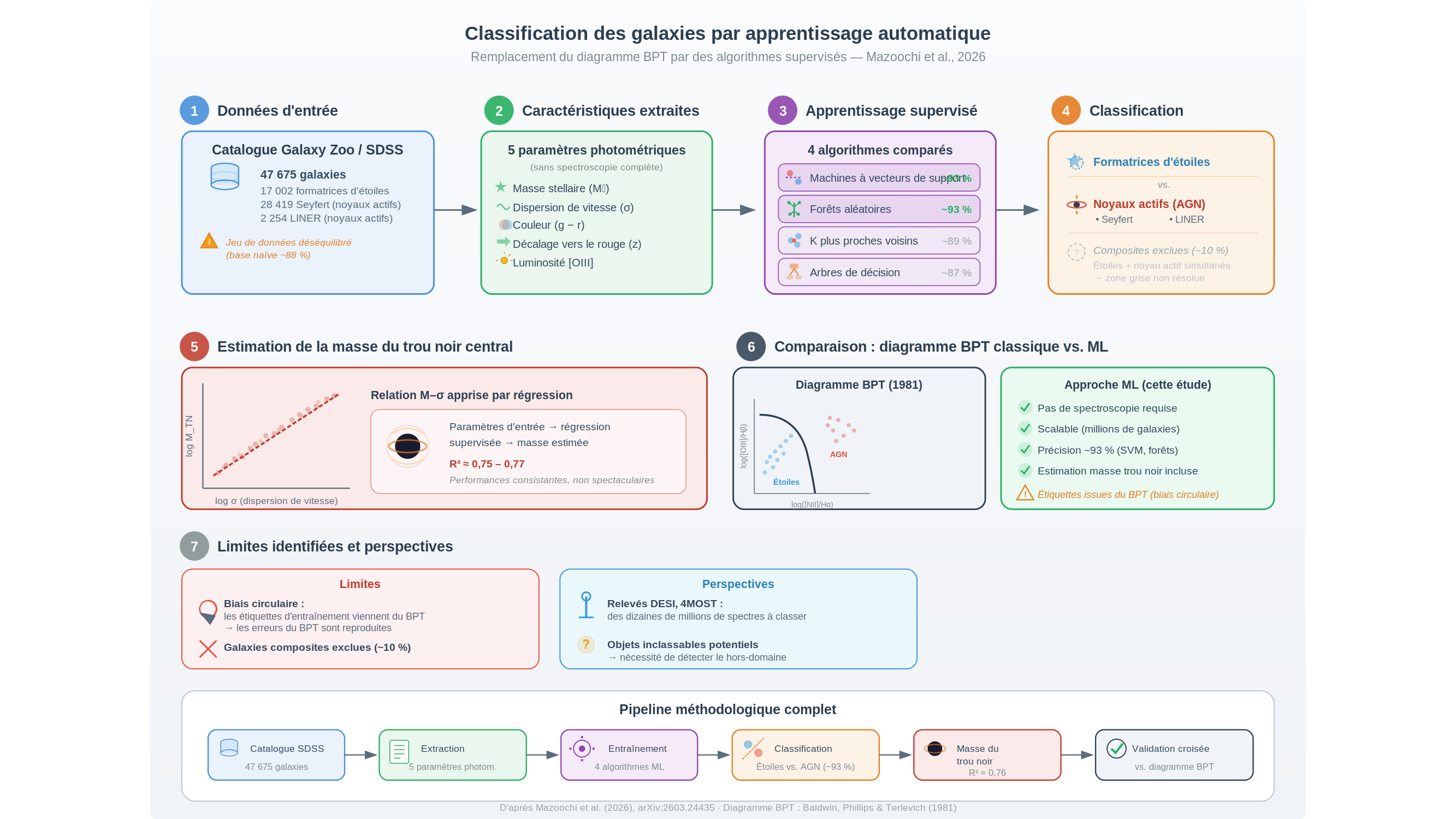
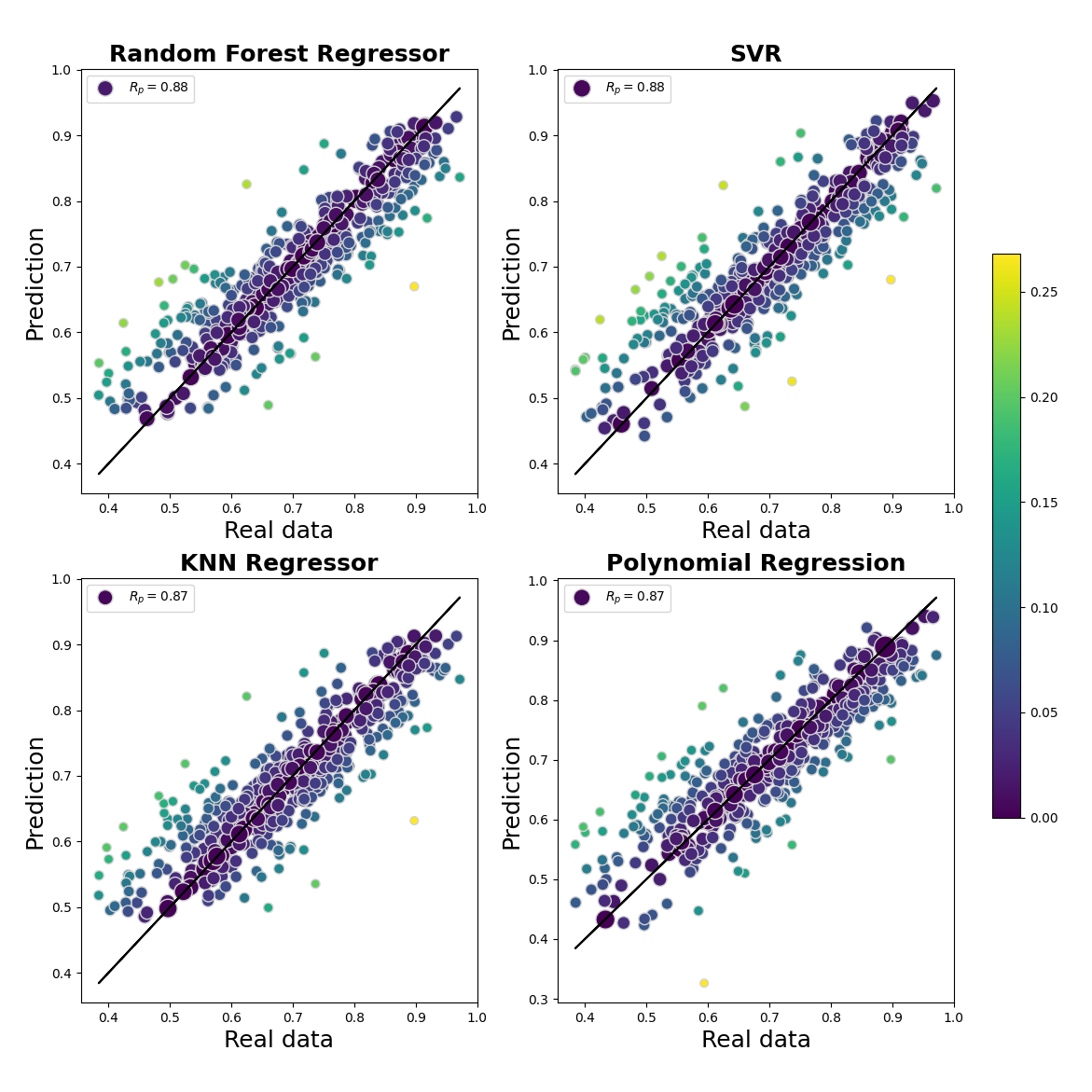
6/ L’équipe pousse l’audace un cran plus loin : estimer la masse du trou noir central de chaque galaxie. Personne ne l’a jamais vu directement — on infère son existence par la danse des étoiles autour de lui. Les algorithmes exploitent cette même relation entre la dispersion des vitesses stellaires et la masse du monstre tapi au centre. Une triangulation dans l’invisible — avec des coefficients de détermination (R²) autour de 0,75–0,77 : performances consistantes, sans être spectaculaires.
7/ Reste un piège que les auteurs eux-mêmes signalent, et il est redoutable. Les étiquettes d’entraînement proviennent… du BPT lui-même. Si le diagramme classique se trompe sur certaines galaxies — et il se trompe —, les algorithmes héritent de l’erreur et la reproduisent avec une efficacité imperturbable. On n’a pas remplacé le juge : on lui a appris à signer plus vite.
8/ Autre angle mort : les galaxies dites « composites », celles qui forment des étoiles et nourrissent un noyau actif, ont été exclues de l’étude. Elles représentent pourtant près de 10 % du catalogue — une zone grise que ni le BPT ni ses successeurs algorithmiques ne savent encore démêler.
9/ 📚 Source : Mazoochi et al., 2026 (arXiv:2603.24435) · Le diagramme BPT originel : Baldwin, Phillips & Terlevich, 1981 (DOI : 10.1086/130766)
10/ Quand DESI livrera ses prochaines fournées de spectres, il s’y trouvera peut-être des galaxies qu’aucune case du BPT n’a jamais prévues — des objets inclassables, à cheval sur des frontières que personne n’a tracées. La question n’est plus de savoir si les algorithmes trieront plus vite que nous. C’est de savoir si les systèmes seront conçus pour signaler ce qui échappe à leur domaine d’entraînement, plutôt que de forcer l’inclassable dans une boîte trop étroite.
À lire aussi sur Mémorabilité :
- Traduire les mathématiques en preuves formelles vérifiables grâce à l’apprentissage automatique
- Cybersécurité et IA : l’apprentissage contrastif pour des modèles qui tiennent leurs promesses en production
- Cinq millions contre des milliards : le pari d’efficacité d’un système OCR qui bouscule les certitudes
Figures originales du paper
Sources
- Mazoochi F., Karimi R., Zhoolideh Haghighi M. H., Tabatabaei F., « Distinguishing active galaxies from star-forming galaxies using machine learning », prépublication arXiv, 2026. arXiv:2603.24435
- Baldwin J. A., Phillips M. M., Terlevich R., « Classification parameters for the emission-line spectra of extragalactic objects », Publications of the Astronomical Society of the Pacific, 93, 5–19, 1981. DOI: 10.1086/130766


