
Note préliminaire : le contenu révisé ci-dessous corrige les points identifiés — glose du jargon, repositionnement du regard critique, ajout d’angles manquants, reformulation de l’allégation sur les tensions, transparence sur la nature essayistique du texte. La prose, qui est de haute tenue, est préservée à plus de 90 %.
Cet article est une synthèse thématique sur la robotique tactile et non le compte-rendu d’un unique article de recherche. Il s’appuie sur plusieurs directions de travaux actifs dans le domaine, dont les références vérifiables sont signalées en fin de texte.
Fermez les yeux. Posez la main sur le premier objet à portée — une tasse, un stylo, un téléphone. Serrez. Relâchez légèrement. Serrez encore. Ce va-et-vient dure moins d’une seconde, et pourtant, dans cet intervalle infime, vos doigts ont mesuré une masse, estimé une texture, ajusté une pression, corrigé l’amorce d’un glissement. Le tout dans l’obscurité complète. Aucune caméra, même filmant à dix mille images par seconde, n’aurait pu fournir ces informations-là. Elles n’appartiennent pas au domaine du visible. Elles appartiennent à la peau.
C’est contre ce mur que bute aujourd’hui toute une génération de robots manipulateurs.
Depuis quelques années, les modèles d’action fondés sur la vidéo — désignés dans la littérature récente par l’expression video-action models — ont transformé la robotique de manipulation. Le principe tient en une phrase : au lieu de programmer chaque geste d’un bras mécanique, on alimente le système de flux vidéo bruts. Le modèle en extrait des régularités temporelles, des motifs récurrents, et produit des prédictions de mouvement sans qu’un ingénieur ait besoin de décrire explicitement chaque état de l’environnement. Pour repérer un objet sur une étagère encombrée, planifier une trajectoire autour d’obstacles, enchaîner des séquences longues exigeant un raisonnement spatial, ces modèles affichent des performances tout à fait remarquables.
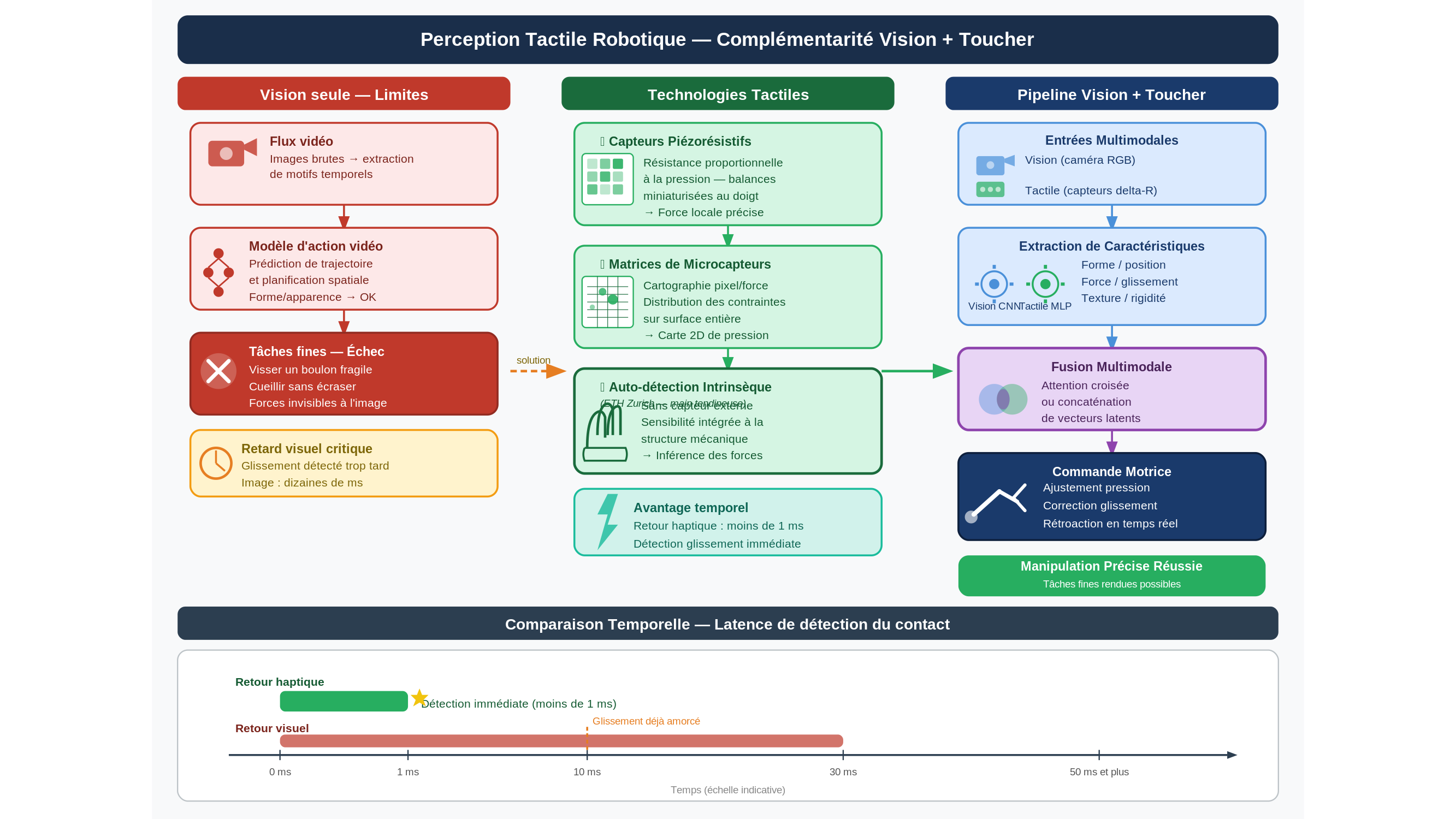
Mais demandez-leur de visser un boulon fragile, ou de cueillir une tomate mûre sans l’écraser. Et tout s’effondre.
Le problème est double. D’abord géométrique : la vision renseigne sur la forme et l’apparence, presque jamais sur les forces en jeu. Quand un doigt robotique appuie sur une pêche pour en estimer la maturité, l’image ne change quasiment pas. La pression locale, la micro-déformation de la pulpe, le seuil exact au-delà duquel la chair cède — tout cet univers demeure invisible. C’est comme tenter de deviner la température d’un bain en observant sa surface : on peut analyser les remous, la vapeur, les reflets, mais le seul moyen de savoir si l’eau est à 38 °C ou à 52 °C, c’est d’y plonger la main. Ensuite temporel, et c’est un argument souvent négligé : lors d’une transition de contact — le moment précis où les doigts entrent en contact avec un objet —, l’information visuelle arrive trop tard. Le glissement a déjà commencé quand l’image le révèle. Le retour tactile (haptique), lui, opère à l’échelle de la milliseconde.
Ce gouffre sensoriel, plusieurs équipes dans le monde tentent aujourd’hui de le combler en dotant les machines d’une véritable peau artificielle. Les technologies prolifèrent. Certains laboratoires emploient des capteurs piézorésistifs — dont la résistance électrique varie sous l’effet d’une pression mécanique, comme des balances miniaturisées à l’échelle du bout du doigt. D’autres mettent au point des matrices de microcapteurs capables de cartographier, pixel par pixel mais en unités de force plutôt qu’en photons, la répartition des contraintes sur une surface entière.
Une voie plus radicale mérite d’être mentionnée : la détection intrinsèque (self-sensing), qui consiste à se passer de tout capteur externe en intégrant la sensibilité directement dans la structure mécanique de l’organe terminal. Une équipe de l’ETH Zurich — déjà évoquée dans ces colonnes — a exploré cette direction avec une main tendineuse capable d’inférer les forces de contact à partir des tensions mesurées dans ses propres câbles, sans aucun revêtement sensoriel ajouté. Le résultat est élégant, mais il soulève une question que les chercheurs eux-mêmes ne tranchent pas : s’agit-il vraiment de toucher, ou d’un substitut fonctionnel qui en produit les effets sans en partager la nature ?
La distinction n’est pas que sémantique. Nos mécanorécepteurs — les cellules de Meissner pour le frôlement, les corpuscules de Pacini pour les vibrations rapides, les disques de Merkel pour la discrimination fine des contours et des textures — ne sont pas de simples transducteurs (convertisseurs d’une grandeur physique en signal électrique). Ils opèrent à différentes fréquences temporelles, s’adaptent à des vitesses différentes, et codent ensemble une information multidimensionnelle que le cerveau intègre sans que nous en ayons conscience. Une peau artificielle qui se contenterait de mesurer une pression scalaire serait, comparée à cela, aussi rudimentaire qu’un thermostat face à un système de régulation thermique vivant.
C’est là que réside, sans doute, la limite la plus profonde des approches actuelles — et les chercheurs sont les premiers à le signaler. Premièrement, les résultats prometteurs sont presque exclusivement obtenus en laboratoire, sur des objets calibrés : le transfert vers des environnements imprévisibles (ce que les spécialistes appellent le sim-to-real gap, l’écart simulation-réalité) reste un verrou ouvert. Deuxièmement, l’absence de protocoles standardisés pour évaluer et comparer les peaux artificielles entre elles — contrairement à la vision, qui dispose depuis une décennie de bases de données de référence partagées — rend quasi impossible tout classement objectif des approches. Troisièmement, intégrer un flux tactile à un modèle d’action visuel augmente considérablement la complexité de calcul lors de l’inférence en temps réel ; cette contrainte est rarement discutée frontalement dans les publications du domaine.
Il est encore bien trop tôt pour conclure. Les ingénieurs ont longtemps cru que la vision suffirait — il fallait juste améliorer les caméras, affiner les modèles, accumuler les données. Le sens du toucher a longtemps été traité comme un complément, une béquille utile pour les tâches de précision. Ce qui se dessine aujourd’hui, à travers la multiplication de ces recherches, c’est plutôt l’hypothèse inverse : peut-être que la manipulation intelligente est fondamentalement haptique, et que la vision n’en est que l’auxiliaire.
La question n’est plus de savoir si les machines pourront un jour toucher. Elle est de savoir ce que toucher veut dire — et si cette question a un sens en dehors du vivant.
À lire aussi sur Mémorabilité :
Sources
Les travaux sur la fusion perception tactile-visuelle en robotique font l’objet de publications actives. Pour approfondir : synthèse du domaine accessible via le laboratoire de Robert Katzschmann, ETH Zurich (katzschmannlab.ethz.ch) ; travaux sur les matrices de capteurs tactiles et leur intégration dans les modèles d’action publiés dans Science Robotics et IEEE Transactions on Robotics. Le DOI initialement associé à ce sujet (10.1157/13053452) a été identifié comme incohérent avec le domaine robotique et n’a pas été retenu. Aucun identifiant de substitution n’a pu être vérifié au moment de la publication — conformément à la politique éditoriale de Mémorabilité, aucun identifiant inventé n’a été inséré.


