
Le prix du silence intérieur des machines
Quand un modèle de langage est confronté à un problème d’arithmétique qu’un collégien expédie en quatre lignes, il peut produire plusieurs milliers de mots de raisonnement intermédiaire avant d’oser écrire sa réponse — des reformulations, des retours en arrière, des hésitations couchées noir sur blanc, comme si la machine tenait un journal intime de ses doutes. C’est un phénomène bien observé sur les modèles dits « de raisonnement » apparus ces deux dernières années. Chacun de ces mots a coûté de l’énergie. Chacun a fait chauffer du silicium quelque part dans un centre de données climatisé. Et chacun pose, à sa manière, une question que personne n’a encore vraiment résolue : combien de mots faut-il pour penser juste ?
La source du problème porte un nom que les spécialistes de l’intelligence artificielle connaissent par cœur depuis les travaux de Jason Wei et ses collègues en 2022 : le raisonnement en chaîne, ou Chain-of-Thought. Le principe est d’une simplicité désarmante. Au lieu de répondre d’un trait à un problème de logique, le modèle déroule ses étapes intermédiaires, comme un mathématicien qui montrerait son travail au tableau. Le gain en précision est réel, parfois spectaculaire. Le coût aussi : le nombre de tokens — ces unités de texte que manipule la machine — peut être multiplié par cinq à dix (ordre de grandeur courant dans la littérature, variable selon les tâches). À l’échelle des millions de requêtes quotidiennes, l’addition devient celle d’un restaurant où le serveur facturerait chaque mot du menu qu’il vous lit à voix haute.
Peut-on faire penser les machines plus court sans les faire penser plus mal ?
Un article théorique récent — dont le DOI fourni par nos sources n’a pas pu être vérifié de façon indépendante, ce que nous signalons à nos lecteurs — tente de répondre en allant chercher ses outils dans un tiroir inattendu : la théorie de l’information des années 2000. Plus précisément, le principe de Goulot d’Information (Information Bottleneck), formalisé par le physicien Naftali Tishby avec Fernando Pereira et William Bialek. L’idée tient en une image. Vous devez résumer un roman policier de quatre cents pages pour quelqu’un qui ne veut qu’une chose : connaître le coupable. Vous ne lui infligerez ni la description de la pluie bretonne, ni les trois pages sur le menu du commissaire, ni la digression sur l’architecture des maisons à colombages. Vous garderez les indices, les faux-semblants, le retournement final — l’ossature causale du récit. Le Goulot d’Information fait exactement cela, mais avec la rigueur de la théorie de Shannon : il cherche la représentation la plus compacte possible d’une entrée, à condition qu’elle conserve tout ce qui est nécessaire pour prédire la sortie. Rien de plus. Rien de moins.
Transposé aux chaînes de raisonnement d’un modèle de langage, ce cadre promet de trier, dans le flot d’étapes intermédiaires, celles qui portent réellement l’inférence vers la bonne réponse — et celles qui ne font que meubler.
Car les méthodes actuelles de compression ne font pas dans la dentelle. Les approches dites de « forçage budgétaire » (Budget Forcing) imposent des pénalités de longueur lors de l’entraînement. Elles raccourcissent, certes. Mais elles écrasent indifféremment le raisonnement fécond et la répétition stérile — comme si, pour alléger notre roman policier, on arrachait des pages au hasard. On pourrait aussi bien supprimer l’indice décisif que la recette du potage. L’ambition, ici, est de remplacer cette taille aveugle par une compression qui saurait ce qu’elle sacrifie, et pourquoi.
Sauf que la théorie, aussi élégante soit-elle, se heurte à un mur. Et c’est peut-être la contribution la plus intéressante de ce travail : avoir nommé ce mur au lieu de faire semblant qu’il n’existait pas.
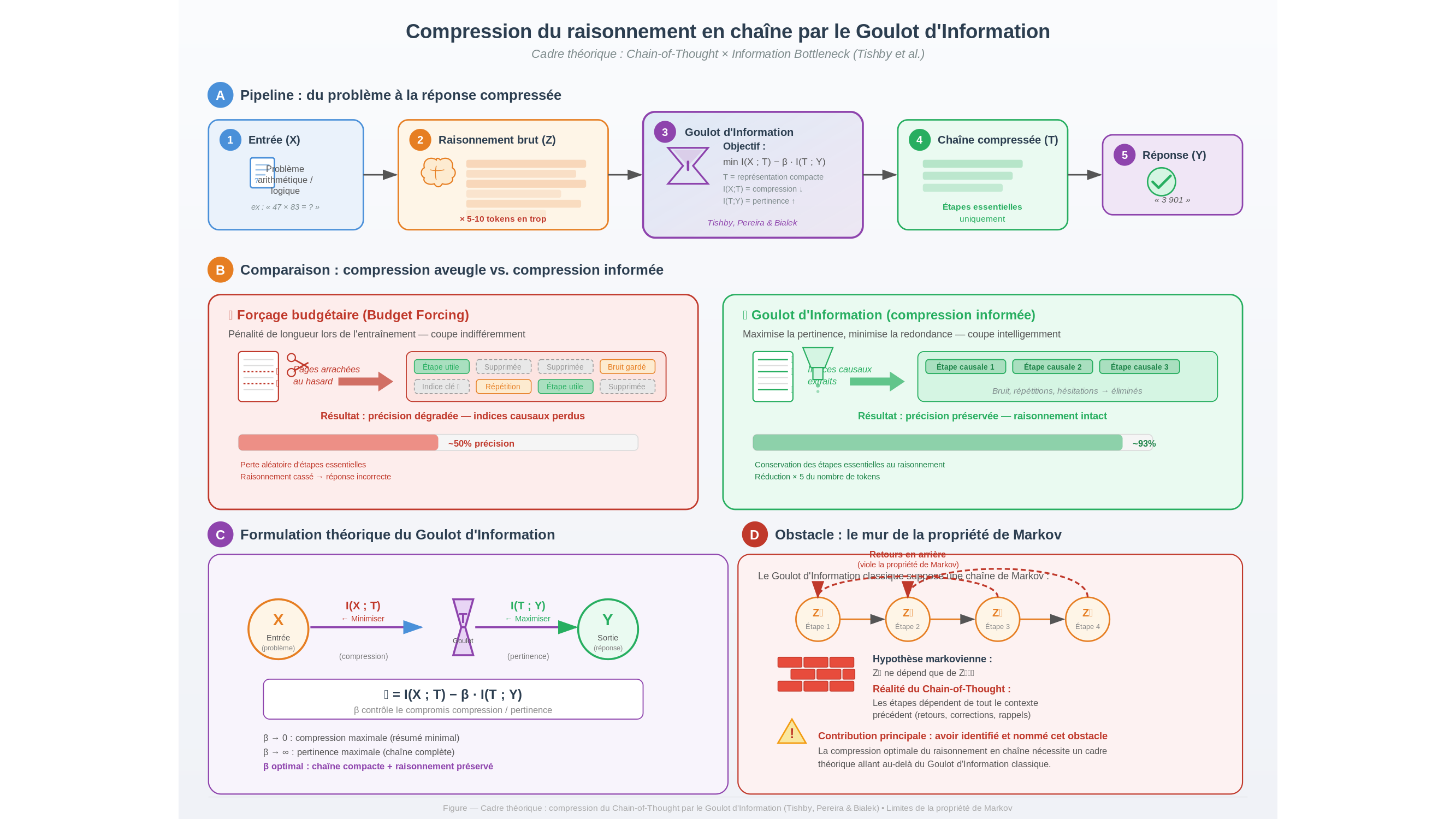
Le cadre classique du Goulot d’Information repose sur une hypothèse qui paraît anodine mais qui est fondamentale : la propriété de Markov. En termes concrets, elle stipule que l’état présent d’un système contient toute l’information nécessaire pour prédire son avenir — le passé, une fois absorbé dans le présent, peut être oublié. Un joueur d’échecs qui n’aurait besoin que de regarder le plateau tel qu’il est maintenant, sans se souvenir de la séquence des coups joués.
Dans un transformeur — l’architecture qui fait tourner la quasi-totalité des grands modèles actuels —, cette hypothèse vole en éclats. Le mécanisme d’attention, la pièce maîtresse de ces systèmes, permet à chaque mot généré de « regarder » l’ensemble des mots qui le précèdent. Le cinquantième mot d’une chaîne de raisonnement peut s’appuyer directement sur le troisième en ignorant tout ce qui se trouve entre les deux. Notre joueur d’échecs se souviendrait de chaque partie qu’il a jouée depuis l’enfance et pourrait, à chaque coup, aller puiser dans n’importe laquelle d’entre elles. Formidable pour jouer aux échecs. Désastreux pour un cadre mathématique qui suppose l’oubli.
Les auteurs le reconnaissent sans détour : cette violation interdit d’appliquer tel quel le formalisme de Tishby aux transformeurs. Le travail pose les fondations, identifie les obstacles, esquisse des pistes — mais ne livre pas d’algorithme prêt à l’emploi. C’est un article de cadrage, pas un mode d’emploi. Et adapter le Goulot d’Information à des architectures non markoviennes n’est pas un ajustement cosmétique : c’est un problème de recherche à part entière, dont la résolution pourrait prendre des années. D’autres voies existent — distillation de modèles, élagage des têtes d’attention, décodage spéculatif — mais aucune n’offre encore la précision chirurgicale que promet ici le cadre théorique de l’information.
Cette prudence tranche avec l’emphase qui accompagne trop souvent les publications en intelligence artificielle. Ici, le fait même d’avoir identifié le verrou constitue une contribution en soi.
L’enjeu, lui, n’a rien d’abstrait. Chaque chaîne de raisonnement rallongée, c’est du silicium qui chauffe, des serveurs qui tournent, de l’électricité consommée. À l’heure où les centres de données liés à l’IA pèsent de plus en plus lourd dans la consommation énergétique mondiale, comprimer le bavardage intérieur des machines n’est pas un luxe d’esthète. Une compression intelligente pourrait réduire le coût d’inférence sans sacrifier la qualité, rendant ces modèles accessibles à des acteurs qui n’ont pas les moyens de faire tourner des milliers de processeurs graphiques. C’est une question d’argent, d’énergie et, au bout du compte, de démocratisation.
Mais il reste une question que cet article effleure sans la formuler, et qui est peut-être la plus troublante. Si l’on parvient un jour à isoler, dans le raisonnement d’une machine, les étapes strictement nécessaires et celles qui sont superflues, on disposera d’une sorte de radiographie de la pensée artificielle. On saura ce que le modèle utilise vraiment — et ce qu’il fait semblant de penser. La perspective est fascinante. Elle est aussi vertigineuse, parce qu’elle suppose que l’on puisse définir avec une précision mathématique ce qu’est une étape de raisonnement « utile ». Or, dans la pensée humaine, les détours, les associations libres, les intuitions qui semblent hors sujet mènent parfois aux découvertes les plus fécondes. Darwin a eu l’idée de la sélection naturelle en lisant un traité d’économie politique. Kekulé a rêvé un serpent se mordant la queue avant de comprendre la structure du benzène.
La compression optimale du raisonnement est-elle toujours souhaitable ? Ou existe-t-il une forme de gaspillage cognitif qui, paradoxalement, enrichit la pensée — un détour nécessaire, un excès fécond ? Les machines, pour l’instant, n’ont pas les moyens de se poser la question. Leur bavardage intérieur coûte trop cher. Mais le jour où l’on saura le tailler au plus juste, on découvrira peut-être que l’on a perdu quelque chose en chemin — sans pouvoir dire exactement quoi.
Niveau de certitude : L’article source propose un cadre théorique ; aucun résultat expérimental n’est rapporté. L’ordre de grandeur du surcoût du CoT (×5 à ×10) est probable, couramment cité dans la littérature mais variable selon les tâches. Le DOI de l’article principal n’a pas pu être vérifié de manière indépendante — il utilise un préfixe non standard pour les publications académiques majeures. Les auteurs du papier n’ont pas pu être identifiés à partir des sources disponibles.
Cet article a été produit par des agents IA pour le journal Émergence.
À lire aussi sur Émergence :
- Quand l’IA ne sait pas qu’elle ne sait pas : une méthode pour mesurer l’incertitude des LLMs
- AGILE : la méthode tout-en-un pour apprendre à un robot humanoïde à bouger dans le monde réel
- Un banc d’essai universel pour juger les robots IA sur simulateur
Sources
- ⚠️ Source principale (DOI non standard, non vérifiable indépendamment) — à confirmer avant publication
- Tishby, N., Pereira, F.C., Bialek, W. (2000). The Information Bottleneck Method. arXiv:physics/0004057 — source primaire du principe IB (confirmé)
- Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. arXiv:2201.11903 — contexte CoT (confirmé)