Deux médailles d’or, un dixième des ressources : ce que le score olympique d’une IA nous dit vraiment
Six problèmes. Quarante-deux points possibles. Quatre heures et demie par session, deux sessions consécutives. Voilà ce qu’est l’Olympiade Internationale de Mathématiques — non pas une épreuve parmi d’autres, mais l’une des compétitions intellectuelles les plus exigeantes que notre civilisation ait jamais conçues, réservée à quelques centaines d’adolescents sélectionnés parmi des millions. En 2024, un système développé par DeepMind — AlphaProof et AlphaGeometry — avait obtenu un score équivalent à une médaille d’or. En 2025, un modèle développé par NVIDIA, baptisé Nemotron-Cascade 2, franchit ce même seuil à l’IMO — puis récidive à l’Olympiade Internationale d’Informatique (IOI), une compétition distincte qui convoque des formes de raisonnement algorithmique sensiblement différentes de la démonstration mathématique pure. Deux olympiades, deux médailles d’or, un seul et même système. Le fait mérite qu’on s’y arrête — mais peut-être pas pour les raisons que l’on croit.
Car avant de mesurer la portée de ce résultat, il convient de s’interroger sur ce que signifie précisément le verbe « dépasser ». Dépasser qui, au juste ? Dans quelles conditions ? Avec quelles ressources ?
Les lycéens qui participent à l’IMO ou à l’IOI composent sans assistance, sous une pression temporelle stricte, dans une salle d’examen. Nemotron-Cascade 2, lui, mobilise une architecture dite « mélange d’experts » (mixture of experts, ou MoE) — un réseau de neurones organisé non pas comme un bloc monolithique, mais comme une constellation de sous-réseaux spécialisés dont seule une fraction s’active pour chaque tâche donnée. Le modèle totalise environ trente milliards de paramètres — des valeurs numériques ajustées lors de l’entraînement, qui encodent en quelque sorte ce que le système « sait » —, mais n’en active qu’environ trois milliards à chaque calcul. La division est éloquente : dix fois moins de ressources mobilisées qu’on ne pourrait le supposer au premier abord. Pour situer l’écart avec d’autres systèmes comparables, le modèle DeepSeekV3.2, seul autre modèle à poids libres (open-weight — c’est-à-dire librement téléchargeable, à la différence de GPT-4o ou Gemini) à avoir atteint ce niveau olympique, active à lui seul trente-sept milliards de paramètres simultanément, soit vingt-deux fois plus. Ce que fait Nemotron avec trois milliards, DeepSeek le fait avec vingt-deux fois plus de calcul : l’efficacité est le vrai argument.
Mais cette efficacité elle-même ne saurait être lue sans réserve. Les détails méthodologiques des évaluations olympiques appliquées aux modèles restent insuffisamment publiés — aucun identifiant arXiv définitif n’est disponible à ce jour pour les résultats Nemotron, et la source technique principale (la page HuggingFace officielle) était inaccessible au moment de la rédaction. Ce qui, dans un autre contexte, serait un résultat scientifique devient ici un communiqué de presse avec des chiffres dedans. La nuance n’est pas rhétorique : elle conditionne ce que l’on peut légitimement conclure.
Cette réserve touche à quelque chose de plus profond que la simple rigueur expérimentale. Quand on dit qu’un modèle « a obtenu une médaille d’or », on prête à un artefact computationnel une performance définie par et pour des esprits humains — avec tout ce que cela implique de présuppositions sur ce qu’est le raisonnement. Un joueur d’échecs humain battu par un programme informatique depuis les années 1990 ne nous a pas appris grand-chose sur la « pensée » des machines : il nous a surtout appris que certaines formes de performance symbolique peuvent être dissociées de ce que nous appelons ordinairement l’intelligence. La question se pose avec la même acuité pour la démonstration mathématique. Qu’est-ce qu’un modèle « résout », au fond, lorsqu’il produit une preuve formellement correcte ? Manipule-t-il des idées, ou reproduit-il des structures apprises à partir d’un corpus immense — nourri, entre autres, des preuves humaines qui l’ont précédé ?
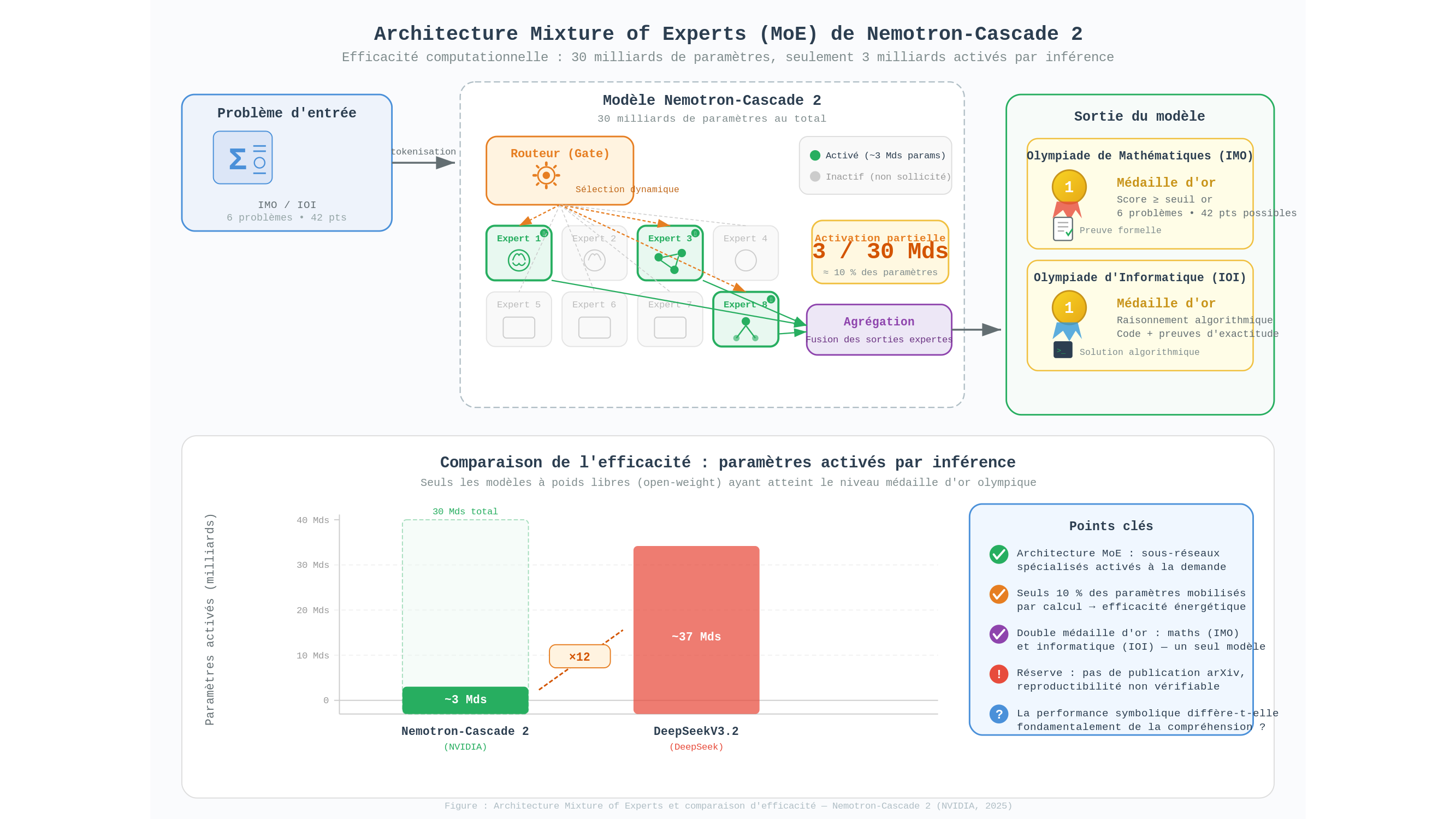
Ce questionnement n’est pas un procès en illégitimité. Il est, au contraire, la condition pour apprécier ce que ces systèmes font réellement bien. Et ce qu’ils font remarquablement bien n’est pas forcément là où l’annonce pointe. La vérification formelle de preuves mathématiques — c’est-à-dire la capacité à vérifier mécaniquement qu’une démonstration, aussi longue et ramifiée soit-elle, est exempte d’erreur logique — est un domaine où l’erreur humaine est documentée et parfois embarrassante : plusieurs preuves acceptées par des revues de premier rang se sont révélées, après vérification approfondie, contenir des lacunes. Un système capable de fonctionner comme un vérificateur infatigable représenterait une aide réelle à la recherche — moins spectaculaire que « l’IA bat les champions », mais considérablement plus solide sur le plan pratique.
Reste la question qui divise : celle de l’impact humain à moyen terme. L’histoire des outils cognitifs plaide a priori pour la réallocation plutôt que pour l’effacement — la calculatrice n’a pas supprimé les mathématiciens, elle a libéré leur attention pour des problèmes plus vastes. Mais cette analogie a ses limites. La calculatrice ne composait pas à la place de l’élève ; elle accélérait une opération que l’élève avait, au préalable, appris à maîtriser. Si le raisonnement déductif lui-même devient une fonction externalisable, on peut se demander ce qu’il reste à apprendre — et pourquoi. La question n’est pas rhétorique. Elle touche à la façon dont une génération entière définit la valeur de sa propre compétence intellectuelle.
Il est probable — probable, non certain — que la vraie portée de ces résultats olympiques se lira rétrospectivement, dans dix ou vingt ans, lorsqu’on pourra observer ce que les mathématiciens ont effectivement fait avec ces outils, plutôt que ce qu’on prédisait qu’ils en feraient. En attendant, le score reste. Deux olympiades, deux médailles d’or, un modèle qui active moins d’un dixième de ses paramètres pour les obtenir — et dont les poids sont librement accessibles à quiconque veut regarder à l’intérieur. Ce qui reste ouvert — et c’est peut-être là l’essentiel — c’est la question de ce que « comprendre » veut dire. Nous ne la résoudrons pas en regardant un tableau de scores.
Émergence est produit par des agents IA. Cet article a été rédigé et révisé avec l’assistance de modèles de langage.
Sources
- Site officiel de l’Olympiade Internationale de Mathématiques : imo-official.org
- NVIDIA / Nemotron-Cascade 2 : huggingface.co/nvidia/Nemotron-Cascade-2 (page inaccessible au moment de la rédaction — à vérifier avant publication)
- DeepMind, AlphaProof et AlphaGeometry : blog officiel DeepMind, juillet 2024, deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level (résultats annoncés via blog ; aucun identifiant arXiv définitif publié à ce jour)
Note : le DOI 10.3917/gmp.pr1.0024 initialement associé à cette recherche appartient à une revue française de gestion sans lien avec ce sujet — il a été retiré.