
La superintelligence n’aura pas lieu — du moins pas celle qu’on imaginait
En janvier 2025, DeepSeek-R1 — un modèle de raisonnement publié par une entreprise chinoise avec un budget déclaré de six millions de dollars, soit environ cent fois moins que ses concurrents américains — obtenait des performances comparables à GPT-o1 sur les benchmarks de mathématiques et de logique formelle. La presse technologique y vit une disruption. Les chercheurs en architecture des systèmes y virent autre chose : la confirmation que la puissance brute n’est pas la bonne variable à optimiser. Ce que DeepSeek-R1 avait fait, c’est apprendre à organiser son calcul — à montrer son travail, étape par étape, à se contredire en chemin. Non plus un oracle, mais une délibération.
Cette distinction — entre puissance et organisation — est précisément au cœur d’un article académique récent publié sur Cairn.info (DOI : 10.3917/gmp.pr1.0008). Son argument central : le modèle dominant de la superintelligence, celui d’un cerveau-dieu solitaire et omniscient, est non seulement peu vraisemblable techniquement, il est fondé sur une métaphore de l’intelligence profondément incorrecte.
Ce que Minsky avait compris en 1986
L’ironie de l’histoire est que la bonne métaphore avait déjà été proposée, quarante ans avant les grands modèles de langage. En 1986, Marvin Minsky publiait The Society of Mind — thèse alors jugée spéculative : l’intelligence n’est pas une propriété unitaire d’un cerveau, mais une propriété émergente d’une société d’agents simples qui interagissent, se spécialisent et se contredisent. Un module traite le langage, un autre gère la mémoire spatiale, un troisième détecte les anomalies. Aucun n’est « intelligent » au sens fort ; leur organisation collective l’est.
Pensez à la façon dont vous résolvez un problème arithmétique difficile mentalement. Vous ne « calculez » pas d’un seul tenant — vous décomposez, vous vérifiez des résultats intermédiaires, vous revenez en arrière quand quelque chose cloche. Ce va-et-vient n’est pas un défaut de votre intelligence : c’est son fonctionnement normal. Ce que Minsky décrivait, c’est exactement ce mécanisme étendu à l’ensemble des facultés cognitives.
Cette description, restée marginale pendant deux décennies, s’avère aujourd’hui être une quasi-prédiction de la trajectoire des systèmes d’IA les plus performants. La tendance architecturale la plus notable de 2024-2025 consiste précisément à faire collaborer plusieurs modèles distincts, chacun spécialisé, chacun pouvant remettre en question les conclusions des autres — AutoGen (Microsoft), LangGraph, CrewAI. Plusieurs modèles jouent des rôles distincts : l’un planifie, un autre vérifie, un troisième critique. Ils se passent des informations, se signalent leurs incohérences, recommencent si nécessaire. Ce n’est plus un cerveau : c’est une équipe.
Le malentendu sur DeepSeek-R1
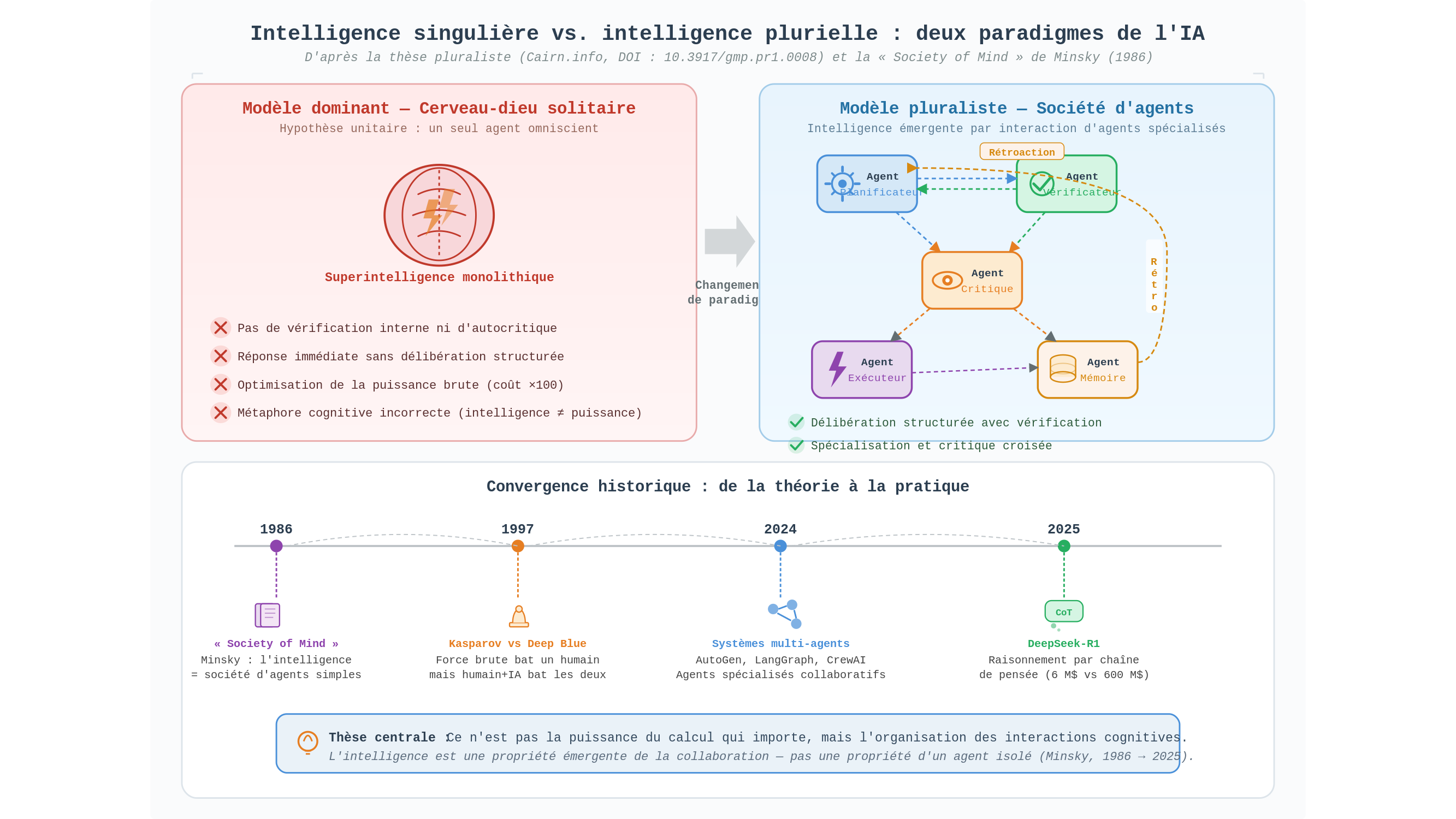
L’article de Cairn mobilise DeepSeek-R1 pour illustrer la thèse pluraliste, mais cette illustration appelle une mise au point technique. Il serait incorrect d’en tirer que « penser plus longtemps ne suffit pas ». C’est plus subtil : DeepSeek-R1 est entraîné par apprentissage par renforcement sur des chaînes de pensée étendues — le modèle apprend à raisonner en montrant son travail. Or l’inference-time scaling, mécanisme mis en avant par OpenAI avec la série o1 en 2024 et que DeepSeek-R1 réplique, montre précisément qu’allouer davantage de calcul à l’inférence améliore les performances. Ce qui compte n’est donc pas la quantité de calcul, mais son organisation. Un modèle qui vérifie, se contredit et révise produit de meilleurs résultats qu’un modèle qui répond immédiatement, même à budget computationnel total identique.
Cette nuance n’est pas anodine. Elle est au cœur de la thèse pluraliste : la structure des interactions cognitives importe davantage que la puissance brute d’un agent unique.
Le résultat de Kasparov — et ses limites
En 1997, Garry Kasparov perd contre Deep Blue. En 1998, il lance un format en apparence anodin : les « Advanced Chess », où des équipes humain-machine s’affrontent. Ce qu’il observe le surprend. Ces équipes hybrides battent aussi bien les meilleurs ordinateurs seuls que les meilleurs joueurs humains seuls. L’intelligence du centaure dépasse celle de ses composantes. L’article de Cairn s’appuie sur cette observation pour défendre un modèle de « symbiose cognitive » humains-IA — non un remplacement, mais une complémentarité.
Ce résultat, établi pour les échecs, est plausible pour d’autres domaines. Mais la complémentarité n’est pas automatique. Elle dépend de la manière dont humain et machine se répartissent les tâches et se corrigent mutuellement. L’écueil est bien documenté : l’automatisation biaisée, où l’humain rassuré par la machine cesse de vérifier ses conclusions. Le centaure peut être plus performant qu’un humain seul, ou il peut hériter des erreurs de la machine sans les détecter. La différence tient à la conception de l’interface entre les deux intelligences — problème ouvert, et d’importance pratique considérable.
La métaphore qui prend le gouvernail
Il faut ici marquer une limite que l’honnêteté intellectuelle impose. Lorsque l’article de Cairn évoque des modèles qui « simulent des débats cognitifs internes spontanés », il glisse de la description mécaniste à la métaphore interprétative — et ne le signale pas assez clairement. Un grand modèle de langage applique des transformations matricielles sur des vecteurs de représentation. Il n’a ni croyances, ni intentions, ni conscience d’une contradiction. Ce qu’on observe — des chaînes de raisonnement qui semblent hésiter, réviser, reconsidérer — est le produit de l’entraînement sur des textes humains qui, eux, reflètent des délibérations authentiques.
Confondre le signal et sa source n’est pas une erreur mineure. Elle produit des attentes mal calibrées, et des politiques d’usage inadaptées. La distinction entre « le modèle se comporte comme s’il délibérait » et « le modèle délibère » n’est pas un détail philosophique réservé aux spécialistes : elle détermine ce qu’on peut raisonnablement lui demander, et comment interpréter ses erreurs.
La question que personne ne tranche encore
L’architecture pluraliste — plusieurs agents qui se contrôlent mutuellement — a un attrait évident : elle ressemble aux institutions humaines qui fonctionnent. La séparation des pouvoirs, la revue par les pairs, le contradictoire judiciaire : ce sont des dispositifs précisément conçus pour corriger les erreurs qu’un agent unique, même compétent, ne voit pas dans son propre raisonnement.
Mais ces institutions ont aussi leur pathologie propre. Les collèges humains produisent des consensus fallacieux, des chambres d’écho, des biais de conformité. Il n’y a aucune raison de principe pour qu’un collège de modèles de langage en soit exempt. La question que ni l’article de Cairn ni la littérature technique ne tranchent encore est précisément celle-ci : à quelle condition une société d’agents IA corrige-t-elle les erreurs plutôt qu’elle ne les amplifie ? La réponse conditionnera, autant que les avancées architecturales elles-mêmes, ce que ces systèmes peuvent faire de fiable.
À lire aussi sur Émergence :
- Le roi boiteux : pourquoi Stable Diffusion XL règne encore sur un trône qu’il ne mérite plus tout à fait
Sources
- https://doi.org/10.3917/gmp.pr1.0008
- https://cairn.info (plateforme d’hébergement probable, éditeur 10.3917)
- Minsky, M. (1986). The Society of Mind — source conceptuelle primaire non citée explicitement mais implicite
- DeepSeek-R1 : https://arxiv.org/abs/2501.12948 (paper technique de référence pour les claims sur DeepSeek-R1)