
Il y a quelque chose d’étrange dans le succès de Stable Diffusion XL. Ouvrez n’importe quel tableau de bord de la plateforme HuggingFace en ce printemps 2026 : le modèle de base cumule plus de deux millions de téléchargements. Des ateliers d’artistes numériques aux chaînes de production des agences de communication, on le retrouve partout, socle discret d’un nombre incalculable d’images générées chaque jour. Et pourtant — et c’est là que ça devient intéressant — ce modèle n’est plus le meilleur. Pas de loin.
Ses concurrents directs, Flux.1 de Black Forest Labs en tête, le surpassent sur la plupart des critères techniques documentés par la communauté : rendu des mains anatomiquement correct, texte lisible intégré dans l’image, cohérence des visages sous des angles inhabituels. Ces comparaisons reposent sur des évaluations communautaires plutôt que sur des benchmarks neutres et universels — il faut le garder à l’esprit — mais le consensus est suffisamment large pour être pris au sérieux. SDXL n’est donc plus au sommet de ce qu’il est censé faire. Il règne quand même. Ce paradoxe mérite qu’on s’y arrête — et pour le comprendre, il faut remonter aux fondations de son architecture.
Pourquoi 1 024 pixels changent tout
Revenons d’abord au problème que SDXL devait résoudre. Son prédécesseur, Stable Diffusion 1.5, travaillait à une résolution native de 512 × 512 pixels — soit 262 144 pixels à traiter simultanément. SDXL opère nativement en 1 024 × 1 024 pixels, c’est-à-dire 1 048 576 pixels. Ce doublement de la dimension linéaire peut sembler modeste sur le papier, mais il se traduit par une multiplication par quatre de la surface totale à traiter. Et les modèles de diffusion ne traitent pas ces pixels comme des cases indépendantes d’une feuille quadrillée : ils doivent maintenir en permanence des cohérences locales et globales, s’assurer que la main au premier plan appartient bien au bras en arrière-plan, que l’ombre tombe dans le bon sens, que la texture de la soie se comporte différemment de celle du coton. Passer à 1 024 pixels sans adapter l’architecture aurait abouti à des dégradations bien connues des utilisateurs de la première génération : membres surnuméraires, artefacts répétitifs comme un papier peint mal aligné, compositions qui s’effondrent dès qu’on s’éloigne du centre.
La solution retenue par Stability AI n’est pas de construire un modèle monolithique toujours plus lourd. C’est une intuition plus élégante, décrite par Podell et al. dans leur article fondateur : diviser le problème en deux, et confier chaque moitié à un spécialiste.
Ce que le modèle lit avant de dessiner
Avant même que la génération commence, SDXL doit interpréter le texte qu’on lui soumet. C’est là qu’intervient l’une de ses innovations les moins visibles mais les plus déterminantes : un double encodeur de texte.
Un encodeur de texte est le composant qui transforme les mots d’une consigne — l’instruction textuelle que vous donnez au modèle — en une représentation numérique que le réseau de neurones peut traiter. Stable Diffusion 1.5 n’en utilisait qu’un. SDXL en emploie deux simultanément : OpenCLIP ViT-bigG, le plus grand encodeur disponible au moment de la sortie du modèle, et CLIP ViT-L, son prédécesseur. Ces deux encodeurs ont été entraînés sur des corpus différents et développent des représentations conceptuelles complémentaires. En combinant leurs sorties, SDXL dispose d’une lecture plus riche et plus nuancée du texte d’entrée — ce qui se traduit concrètement par une meilleure fidélité aux consignes complexes, aux formulations abstraites, aux relations spatiales décrites en langage naturel. C’est en grande partie pour cette raison que « un renard roux assis sur un livre ouvert, lumière dorée de fin d’après-midi, vue de trois quarts » produit un résultat plus fidèle avec SDXL qu’avec ses prédécesseurs.
Un processus en deux actes
Les modèles de diffusion fonctionnent par débruitage progressif. Imaginez qu’on vous tende une feuille entièrement couverte de neige — ce bruit statique des vieilles télévisions analogiques mal accordées — et qu’on vous demande, étape par étape, de la transformer en portrait. À chaque passe, vous disposez de deux informations : ce que vous voyez sur la feuille, et ce qu’on vous a décrit en texte. Vous affinez. Vous guidez. Après cinquante à cent de ces passes, quelque chose de reconnaissable émerge du chaos.
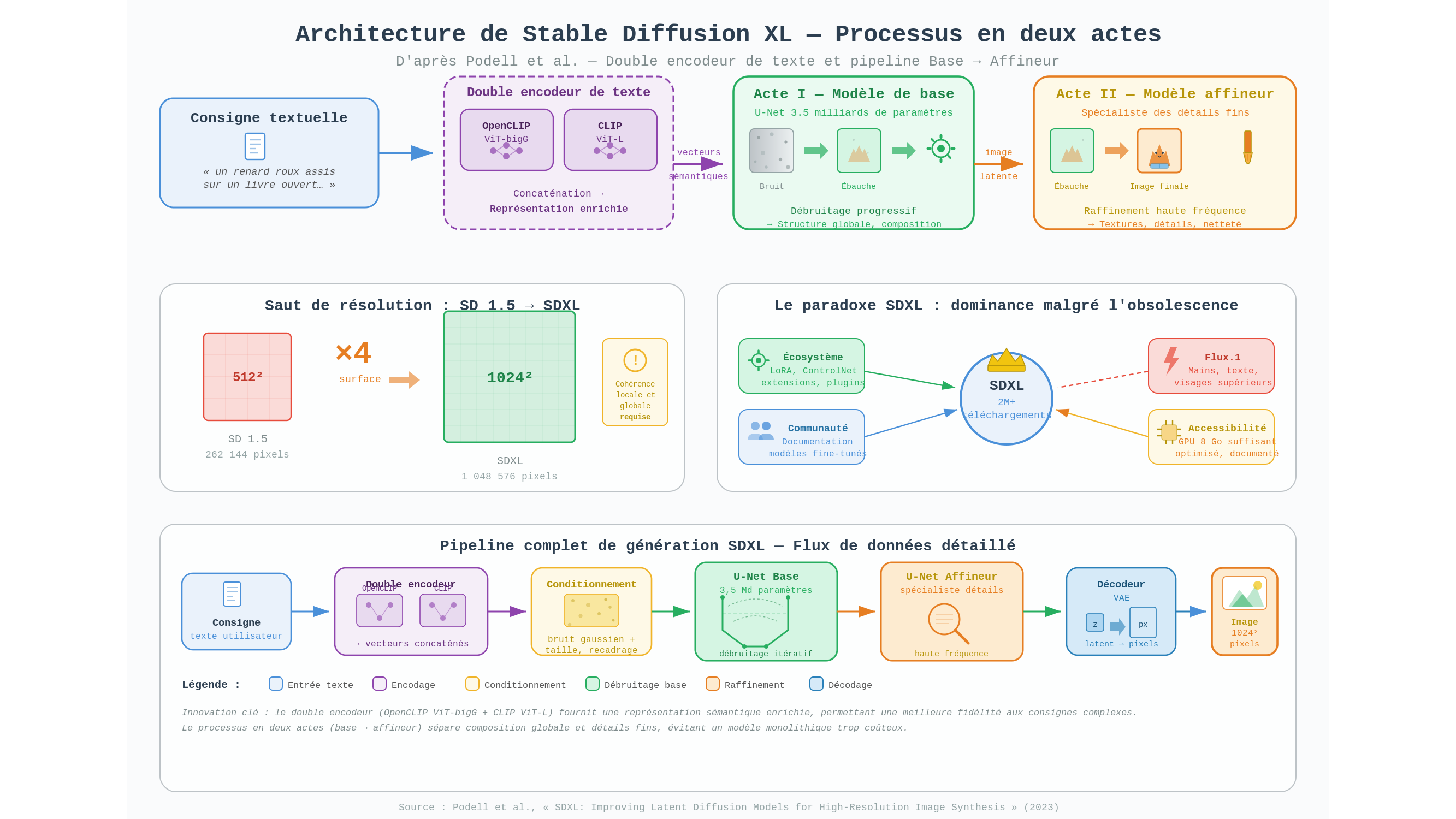
Ce qui distingue SDXL, c’est que ce voyage du bruit vers l’image est désormais partagé entre deux voyageurs distincts. Un modèle de base prend en charge les premières étapes : composition générale, équilibre des masses, structure d’ensemble. Puis un second modèle, le raffineur, hérite du résultat intermédiaire pour travailler sur les détails fins : textures, transitions subtiles, cohérences de surface. Le total des deux représente environ 3,5 milliards de paramètres — base et raffineur confondus — contre 860 millions pour SD 1.5 et 900 millions pour SD 2.x, soit environ quatre fois plus que ses prédécesseurs directs. L’analogie avec l’édition littéraire n’est pas déplacée : imaginez un auteur qui livre une architecture d’arguments solide mais sans finesse de style, puis confie son manuscrit à un correcteur chargé de polir chaque phrase sans toucher au plan d’ensemble. Chaque intervenant est libéré de la contrainte que l’autre gère — et le résultat final dépasse ce que chacun produirait seul.
Cette organisation rappelle, dans l’esprit sinon dans les détails techniques, le principe des architectures à mélange d’experts (mixture of experts) — où différents sous-réseaux se spécialisent sur différentes parties du problème — sans pour autant en constituer une mise en œuvre directe. C’est une parenté conceptuelle, pas une filiation.
Ce même enchaînement base + raffineur peut aussi fonctionner en mode img2img : partir d’une image existante et la modifier selon une consigne textuelle, plutôt que de générer depuis le bruit pur. Cette technique, formalisée sous le nom SDEdit (arXiv:2108.01073), étend les usages de SDXL bien au-delà de la génération pure — retouche guidée, variation stylistique, recomposition partielle.
L’écosystème, vrai moteur du succès
Mais l’architecture seule n’explique pas pourquoi SDXL résiste à des modèles objectivement plus performants sur les métriques standards. La réponse est ailleurs : dans ce qu’on pourrait appeler la dette d’intégration.
Autour de SDXL s’est constitué, en trois ans, un écosystème d’une densité rare. Des milliers d’affinages spécialisés — ces modèles dérivés entraînés sur des corpus ciblés pour maîtriser un style particulier, un domaine précis — sont disponibles librement. Des extensions tierces permettent d’ajouter des contraintes visuelles au processus de génération : imposer une pose précise à un personnage, reproduire la structure d’une composition existante, guider la lumière selon un schéma défini. ControlNet, l’un des plus utilisés de ces composants externes (développé indépendamment par Zhang et al., arXiv:2302.05543), illustre bien ce phénomène : ce n’est pas une fonctionnalité intégrée à SDXL, mais un outil tiers qui s’est greffé sur lui parce que l’architecture était ouverte et documentée. C’est la différence entre un logiciel et une plateforme — et SDXL est devenu une plateforme.
Cette ouverture a un cadre juridique précis : SDXL est distribué sous licence CreativeML Open RAIL++-M, qui encadre les usages abusifs tout en restant accessible à quiconque souhaite l’utiliser, l’étudier ou l’adapter. Une condition nécessaire à la floraison de cet écosystème — et un contraste saisissant avec les modèles propriétaires à accès restreint qui dominent par ailleurs le paysage.
Ce que les métriques ne voient pas
Il faut toutefois résister à la tentation de transformer ce succès en validation technique. Les référentiels d’évaluation standardisés mesurent des capacités précises : rendu des mains, précision anatomique, lisibilité du texte. Sur ces critères, Flux.1 et ses contemporains surclassent SDXL, selon les évaluations publiées et documentées par la communauté. Ce que ces référentiels mesurent moins bien, c’est l’intégration dans des chaînes de production existantes, la disponibilité des extensions, la familiarité accumulée des utilisateurs. SDXL bénéficie d’un avantage que les ingénieurs appellent parfois l’inertie d’adoption — et que les économistes connaissent bien sous le nom d’effet de réseau.
Il y a là une limite réelle, et elle mérite d’être nommée. Si les métriques de qualité ne capturent pas les raisons du succès d’un modèle, c’est peut-être que la communauté optimise pour autre chose que la qualité. Les workflows de production privilégient la reproductibilité, la compatibilité, la prévisibilité — pas nécessairement le meilleur rendu absolu sur un ensemble de test. Ce glissement entre ce qu’on mesure et ce qui compte est un angle mort classique de l’évaluation en apprentissage automatique (machine learning), et SDXL en est un cas d’école.
Un autre angle mort mérite l’attention : la concentration du pouvoir. Les modèles qui surpassent SDXL sur les métriques sont, pour la plupart, moins accessibles, plus coûteux à déployer, ou adossés à des entités commerciales dont les conditions d’utilisation évoluent. L’ouverture de SDXL n’est pas un détail anecdotique — c’est une propriété structurelle qui détermine qui peut l’utiliser, comment, et pour quoi. Une image générée avec un modèle propriétaire à accès restreint appartient, dans une certaine mesure, à celui qui contrôle le modèle.
On pourrait donc formuler autrement le paradoxe initial : SDXL n’est peut-être pas le meilleur modèle de génération d’images, mais il reste le plus libre. Et dans un paysage où les grands modèles se ferment progressivement, cette liberté vaut peut-être plus que quelques points sur un référentiel d’évaluation.
La question qui reste ouverte — et qui ne trouvera pas de réponse dans un article de vulgarisation — est de savoir si cet équilibre tiendra. Les modèles propriétaires continueront d’avancer plus vite, portés par des ressources de calcul que peu d’équipes open source peuvent rivaliser. À quel moment l’écart de qualité deviendra-t-il trop grand pour que l’avantage d’ouverture compense ? Personne ne le sait encore. Et c’est peut-être là la vraie question que pose SDXL — non pas ce qu’il fait, mais combien de temps il peut le faire.
À lire aussi sur Émergence :
- Génération de texte en mode turbo : distiller les modèles de diffusion sans perdre en qualité
- La fidélité des LLMs : un chiffre qui dit tout… sauf la vérité
- Des robots qui gardent le cap même quand tout bouge autour d’eux
Sources
Podell, D. et al. (2023). SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. arXiv:2307.01952
Zhang, L. et al. (2023). Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet). arXiv:2302.05543
Meng, C. et al. (2021). SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. arXiv:2108.01073