KAN et causalité : vers des modèles génératifs enfin ouverts à l’examen
Imaginez qu’on vous remette les clés d’une voiture dont le tableau de bord affiche toutes les données imaginables — vitesse, régime, pression des pneus, température de l’huile — mais dont le moteur reste enfermé dans un bloc de résine opaque. Vous savez quoi, jamais pourquoi. C’est à peu de chose près la situation dans laquelle se trouvent aujourd’hui ceux qui travaillent avec les grands modèles génératifs d’apprentissage profond (deep learning) : des sorties lisibles, des entrailles illisibles. Une prépublication déposée en mars 2026 par Almodóvar et ses collègues (arXiv:2603.20184) propose d’entrouvrir le capot, en mariant deux familles d’idées que l’on avait rarement vues ensemble : les réseaux de Kolmogorov-Arnold, ou KAN, et l’inférence causale. La promesse est séduisante. Les questions qu’elle soulève le sont tout autant.
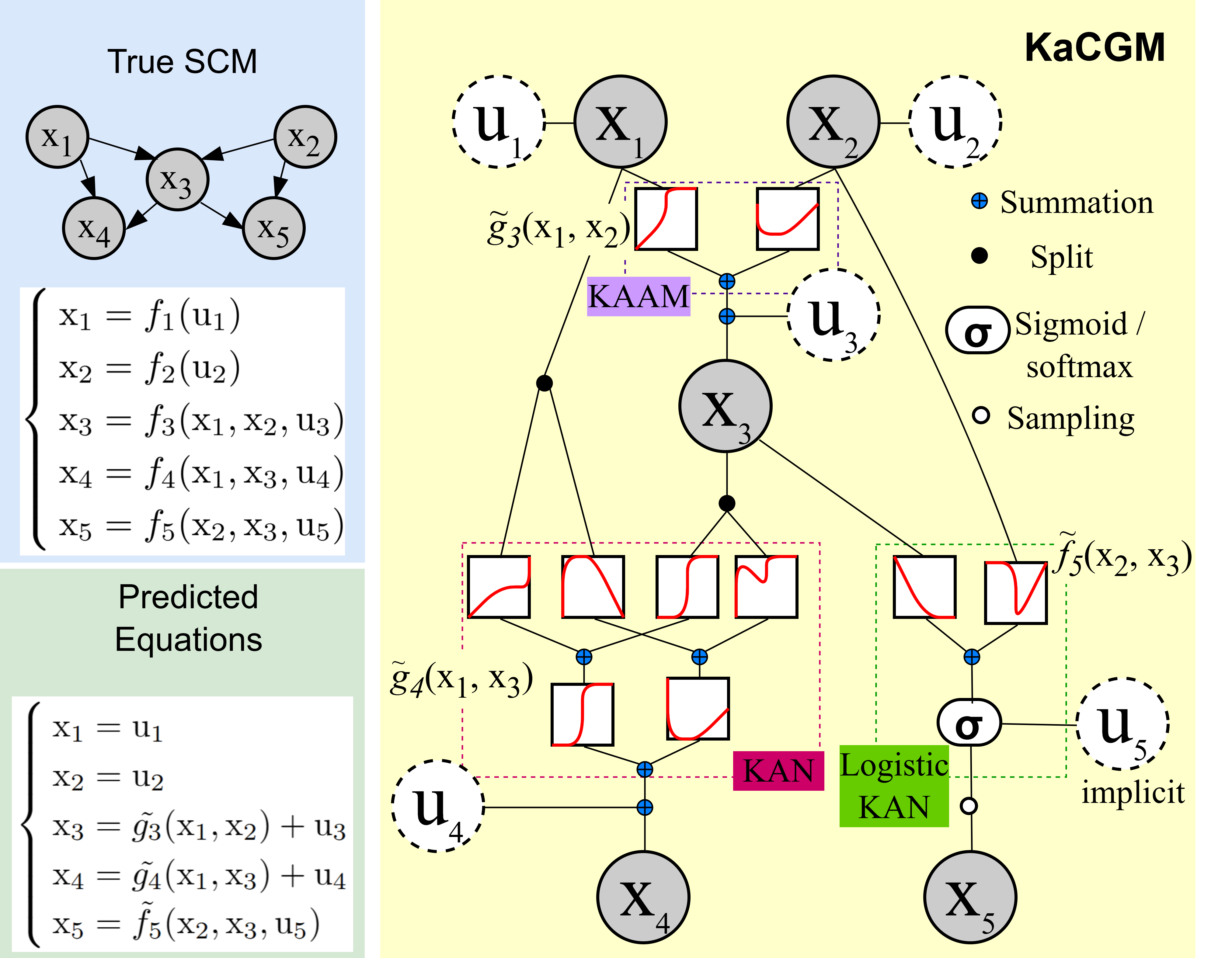
Commençons par le commencement. Les KAN — Kolmogorov-Arnold Networks — sont une architecture d’apprentissage automatique (machine learning) publiée en 2024 par Ziming Liu et ses collaborateurs du MIT (arXiv:2404.19756). Leur particularité tient dans une idée élégante : dans un réseau classique de type perceptron multicouche, les connexions entre neurones transportent des poids fixes, et ce sont les nœuds qui appliquent des fonctions d’activation immuables. Les KAN retournent cette logique : ils placent les fonctions apprenables directement sur les arêtes — les connexions elles-mêmes — sous forme de fonctions univariées que le réseau ajuste pendant l’entraînement. Résultat : les représentations internes deviennent, en théorie, plus modulaires, plus décomposables, plus lisibles. Un réseau KAN bien entraîné peut parfois s’écrire presque comme une formule mathématique explicite. C’est comme si, au lieu d’un moteur fondu dans le bloc, vous pouviez distinguer chaque piston, chaque soupape, chaque arbre à came.
Ce que font Almodóvar et ses co-auteurs, c’est de pousser cette lisibilité un cran plus loin, dans un territoire où elle fait cruellement défaut : l’identification des relations causales dans les modèles génératifs. L’idée centrale, héritée de la hiérarchie causale formulée par Judea Pearl dans Causality (2000), est qu’il ne suffit pas d’observer qu’une variable X précède une variable Y pour conclure que X cause Y. La causalité exige une structure — un graphe orienté de dépendances — que les modèles génératifs standards enfouissent quelque part dans leurs milliards de paramètres sans jamais l’exposer. Les auteurs proposent un cadre — qu’ils nomment KaCGM — où les KAN jouent le rôle de décodeurs capables de rendre ce graphe visible, ou du moins, partiellement visible.
Sur les données synthétiques utilisées dans la prépublication, les résultats sont [PROBABLE] encourageants. Le graphe causal appris ressemble, dans les cas testés, au graphe réel. Les fonctions apprises sur les arêtes sont interprétables. L’architecture tient ses promesses de modularité. Un optimiste peut légitimement y voir un progrès réel sur l’opacité totale des architectures actuelles : une auditabilité partielle, même imparfaite, vaut mieux qu’une boîte noire assumée.
Mais l’histoire ne s’arrête pas là.

Le mot qui mérite d’être retenu, et pesé, est synthétiques. Toute la validation de la prépublication repose sur des environnements construits pour l’occasion — des données propres, des structures causales connues à l’avance, des confondeurs soigneusement maîtrisés. Un confondeur, en causalité, c’est cette variable cachée qui corrèle à la fois votre cause et votre effet apparent sans que rien ne la relie directement à l’un ou à l’autre — comme le niveau socio-économique d’un patient qui influence à la fois son alimentation et son risque cardiovasculaire, et qu’aucun dossier médical ne mentionne. L’histoire de la causalité computationnelle, de Pearl (2000) aux méthodes classiques d’identification causale développées depuis, est jalonnée de techniques qui brillaient sur des cas propres et trébuchaient dès que le monde réel s’invitait à la table — avec ses variables cachées, ses confondeurs non observés, son bruit non gaussien. La question que personne, dans la prépublication, ne semble avoir abordée de front : les auteurs ont-ils délibérément exclu certains types de confondeurs pour tester la robustesse du système ? Le silence sur ce point n’est pas rassurant. Le papier n’a, de surcroît, pas encore été évalué par les pairs — c’est le statut de toute prépublication arXiv — ce qui impose de lire ses conclusions avec la prudence appropriée.
Il y a un risque plus profond encore, et celui-là dépasse la technique. On pourrait l’appeler le piège de l’explicabilité mal calibrée. Un système opaque, tout le monde le sait opaque : les ingénieurs, les auditeurs, les utilisateurs finaux. Cette opacité, inconfortable, génère au moins une méfiance saine. Un système qui montre ses causes — qui affiche un graphe orienté, qui expose ses fonctions d’arête — peut en revanche générer quelque chose de plus insidieux : une confiance injustifiée. Si le graphe affiché est partiellement faux, partiellement incomplet, ou valide uniquement dans les conditions de laboratoire où il a été construit, alors l’utilisateur qui lui fait confiance est dans une situation pire que celui qui sait qu’il ne sait pas. C’est, d’une certaine façon, la même leçon que celle tirée des premières générations de systèmes experts des années 1980 : l’apparence de la raison n’est pas la raison. Et dans un contexte de scoring judiciaire ou de triage médical automatisé, cette confusion peut avoir des conséquences bien réelles.
Ce que suggère finalement ce travail — et c’est peut-être sa contribution la plus durable, au-delà des résultats immédiats — c’est que la direction est bonne. Rendre les modèles génératifs capables de raisonner causalement, et de le faire de manière auditable, est une ambition qui mérite d’être poursuivie. Les KAN offrent un outil architectural intéressant pour progresser dans cette direction. Mais entre une architecture prometteuse sur données synthétiques et un outil déployable dans des contextes décisionnels réels — médical, judiciaire, financier — il y a un gouffre que les évaluations de référence sur données contrôlées ne sauraient combler seuls. Toute utilisation sérieuse devrait exiger une validation sectorielle rigoureuse, sur des données réelles, avec des confondeurs non contrôlés, avant que l’on commence à faire confiance aux causes que le système croit avoir trouvées.
Ce n’est pas un verdict contre KaCGM. C’est un rappel que la maturité ne se décrète pas — elle se mesure à l’épreuve du monde.
Et le monde, lui, n’a jamais été aussi propre que dans un laboratoire.
Sources
Almodóvar et al. (2026). KaCGM : Kolmogorov-Arnold Causal Generative Models. arXiv:2603.20184. https://arxiv.org/abs/2603.20184
Liu, Z. et al. (2024). KAN : Kolmogorov-Arnold Networks. arXiv:2404.19756. https://arxiv.org/abs/2404.19756
Pearl, J. (2000). Causality : Models, Reasoning, and Inference. Cambridge University Press.