Ce que « réagir » veut dire
Il y a, dans le mot « réagir », une présupposition que l’on néglige ordinairement. Réagir, c’est agir en retour — ce qui suppose, logiquement, qu’un intervalle sépare la perception d’un événement de la réponse qu’il provoque. Cet intervalle, chez les êtres vivants, a un nom : le temps de réaction. Les psychologues le mesurent depuis le xix^e siècle ; il oscille, chez l’homme, entre cent cinquante et deux cent cinquante millisecondes selon la modalité sensorielle sollicitée — visuelle, auditive ou tactile. Mais que devient cette notion lorsqu’on la transpose à des machines dont la « perception » est distribuée entre des couches de calcul profondes, et dont le « geste » est le produit d’une inférence statistique ? C’est, en substance, la question que pose un cadre de recherche récent baptisé FASTER — dont l’ambition est moins d’accélérer les robots que de contraindre la robotique à préciser ce qu’elle entend, au juste, par réactivité.
Les modèles dits VLA — pour vision-language-action, soit des architectures capables d’articuler perception visuelle, compréhension du langage naturel et commandes motrices — ont suscité un enthousiasme considérable depuis quelques années. Des systèmes comme RT-2, conçu chez Google DeepMind, ou π0, développé par Physical Intelligence, incarnent cette promesse : un robot qui « voit » son environnement, « comprend » une instruction ordinaire, et « agit » en conséquence. L’idée est séduisante. Elle est aussi, dans sa formulation, légèrement trompeuse — car ces verbes, empruntés au vocabulaire de l’expérience consciente, dissimulent une réalité plus rugueuse.
Ces modèles souffrent d’un délai structurel entre la perception et l’action. Le temps nécessaire pour traiter les entrées et générer une réponse — ce que les ingénieurs nomment le temps d’inférence — se situe couramment entre cent millisecondes et plusieurs secondes. Dans un environnement stable, ce délai importe peu. Dans un environnement qui change — un objet déplacé, un obstacle surgissant, un humain qui traverse le champ d’action — il devient le nœud du problème.
Pour contourner cette lenteur, les chercheurs ont eu recours à ce que l’on appelle l’action chunking — la « prédiction par blocs ». Plutôt que de calculer une action à la fois, le modèle prédit d’un seul tenant une séquence de N actions successives. Le robot exécute ensuite ce bloc en continu, sans solliciter de nouvelle décision à chaque pas. Les trajectoires gagnent en fluidité, le débit global s’améliore. À première vue, tout semble aller mieux.
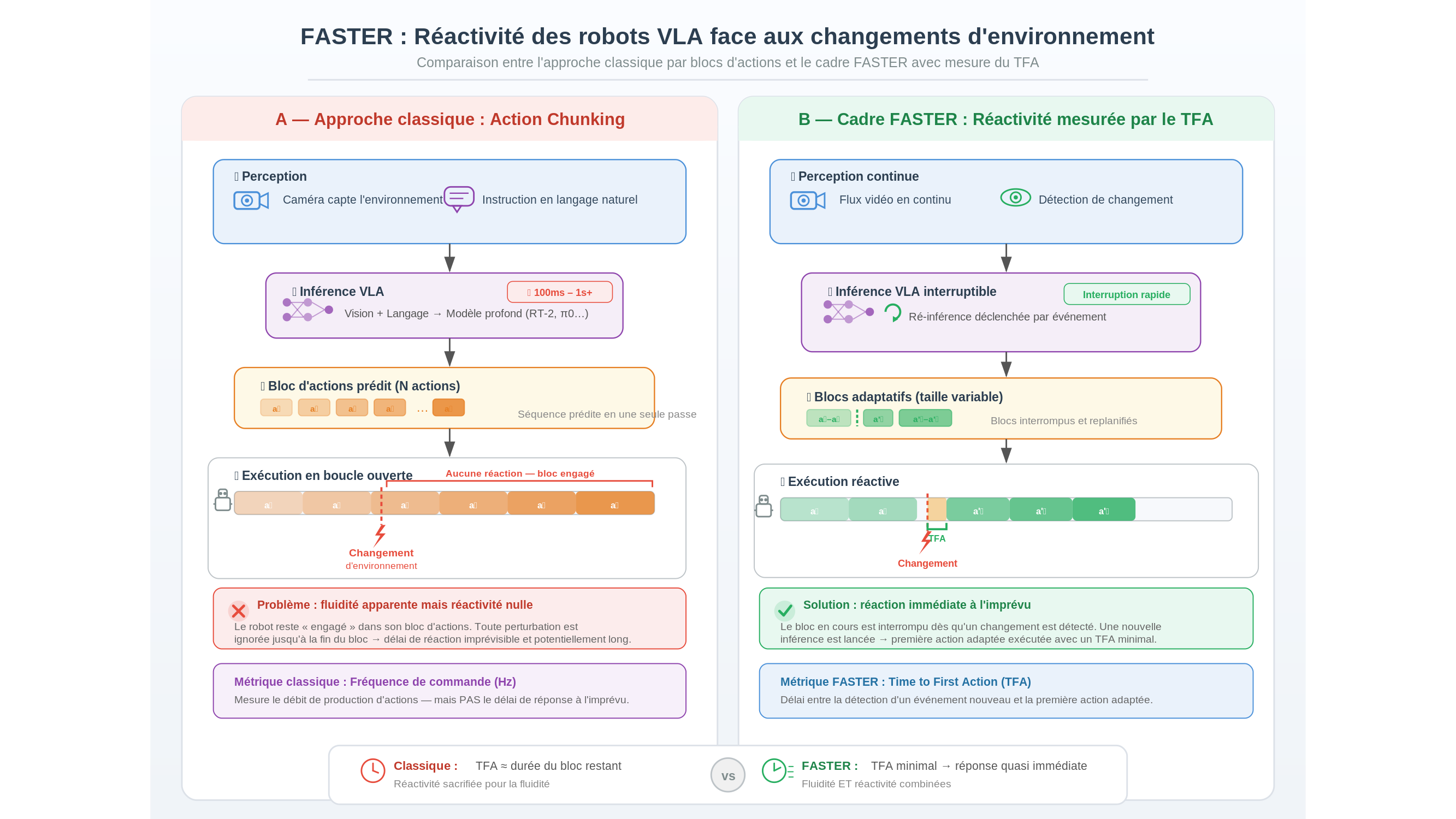
Pensons à un musicien qui joue un morceau mémorisé. Ses mains se déplacent avec une fluidité parfaite ; les notes s’enchaînent sans hésitation visible. Mais si quelqu’un pose un objet sur le clavier pendant qu’il joue, combien de temps lui faudra-t-il pour interrompre le geste en cours, identifier l’obstacle, décider d’une nouvelle trajectoire ? La fluidité de l’exécution n’entretient aucun rapport nécessaire avec ce temps de réponse à l’imprévu. Elle peut même, dans certains cas, l’aggraver : un geste fluide est un geste engagé, difficile à interrompre. C’est exactement le piège que tend l’action chunking aux robots VLA.
En prédisant un bloc de N actions d’un seul tenant, le modèle se lie d’avance. Il ne peut répondre à un changement de l’environnement qu’au terme de l’exécution du bloc, ou en l’interrompant brutalement — ce qui introduit des discontinuités mécaniques problématiques. On a donc gagné en fluidité apparente ce qu’on a perdu en réactivité réelle. La métrique couramment utilisée dans la littérature pour évaluer un modèle robotique — la fréquence à laquelle il produit des commandes — ne capture pas ce coût caché. C’est précisément ce que FASTER cherche à corriger.
Le cadre proposé introduit une mesure plus fine : le Time to First Action (TFA), soit le délai entre la perception d’un événement nouveau et l’exécution de la première commande adaptée à cet événement. Cette mesure est, chose non triviale, indépendante de la fréquence d’inférence globale du modèle. Un robot peut produire des commandes à haute fréquence tout en ayant un TFA élevé, si ces commandes sont planifiées longtemps à l’avance et insensibles aux perturbations de l’instant. La distinction est loin d’être académique : dans les applications où un robot partage l’espace avec des humains — logistique, assistance à domicile, chirurgie assistée —, c’est le TFA qui détermine si le système est sûr.
La proposition architecturale de FASTER repose sur un principe élégant : plutôt que d’imposer au modèle de produire des blocs d’actions uniformément planifiés, on modifie la distribution de la latence à l’intérieur du bloc. Les premières actions du bloc sont générées plus tôt, avec moins d’information mais plus de rapidité ; les actions suivantes bénéficient d’un temps de calcul plus long, donc d’une meilleure qualité d’inférence. Le robot « décide d’abord, affine ensuite » — une logique qui évoque, sans qu’on puisse pousser l’analogie trop loin, le fonctionnement des systèmes nerveux animaux, où la réponse réflexe précède la décision consciente.
Il convient ici de marquer une limite que les auteurs eux-mêmes, dans leur honnêteté, n’esquivent pas. Les évaluations rapportées portent sur des environnements de laboratoire, avec des perturbations introduites de manière contrôlée. La question demeure ouverte de savoir si les gains mesurés sur le TFA se maintiennent dans des scènes plus chaotiques, où plusieurs événements imprévus se superposent à des intervalles inférieurs à la durée d’un bloc. Par ailleurs, la granularité optimale des blocs — faut-il prédire dix actions à la fois, vingt, cinquante ? — dépend fortement de la dynamique propre à chaque tâche, et aucune règle générale n’a été établie à ce stade. Ce que FASTER propose, c’est une métrique et une architecture ; il ne fournit pas encore un algorithme universel de calibrage.
Un autre point mérite d’être signalé. Les modèles VLA de grande taille — ceux qui obtiennent les meilleures performances sur les benchmarks — sont, pour la plupart, développés et contrôlés par un petit nombre d’acteurs industriels. La question de la réactivité temporelle des robots n’est pas séparable de celle des ressources de calcul nécessaires pour l’atteindre. Un modèle qui réduit son TFA en mobilisant des dizaines de milliards de paramètres sur des grappes de processeurs graphiques spécialisés ne répond pas au même problème qu’un modèle embarqué sur un robot mobile à batterie. FASTER, tel qu’il est présenté, ne tranche pas cette question de l’embarquabilité — et c’est là, sans doute, que se jouera la pertinence pratique de l’approche.
On peut se demander, in fine, si la recherche sur les VLA ne bute pas sur une tension fondamentale que la robotique partage, à sa façon, avec la théorie de la connaissance. Comprendre — vraiment comprendre, au sens de modéliser un environnement avec suffisamment de profondeur pour anticiper ses changements — prend du temps. Réagir, lui, exige de l’immédiateté. Ces deux exigences sont, en régime général, contradictoires : plus un système est capable de raisonnement profond, plus son temps de réponse tend à s’allonger. Bergson, qui n’avait jamais entendu parler de transformeurs ni de prétraitement d’image, avait pressenti quelque chose de ce genre lorsqu’il écrivait que la conscience est essentiellement un retard — une hésitation entre plusieurs réponses possibles. Les robots VLA, à leur manière, héritent de cette tension. FASTER ne la résout pas ; il lui donne, au moins, un nom précis et une unité de mesure.
Sources
Ce travail s’appuie sur un accès à la préimpression du cadre FASTER (non encore indexée au moment de la rédaction). Les concepts clés — action chunking, Time to First Action, distribution de la latence intra-bloc — sont documentés dans le résumé de recherche disponible. Une mise à jour des références sera effectuée à la publication officielle.
Pour le contexte sur les modèles vision-language-action et l’action chunking, on pourra consulter les travaux fondateurs accessibles sur arXiv, notamment les publications de l’équipe RT-2 (Google DeepMind) et les travaux de Cheng Chi et al. sur la politique de diffusion (Diffusion Policy, arXiv:2303.04137), qui constituent la référence commune du champ sur la prédiction par blocs.