
L’attention, un luxe superflu ? Quand la physique des taches de léopard défie le paradigme dominant de l’IA
En 1952, Alan Turing publiait un article de morphogenèse — l’étude de l’apparition des formes dans le vivant — dans lequel il proposait des équations différentielles pour expliquer les rayures du zèbre et les taches du léopard. Personne, à l’époque, n’imaginait que ces mêmes équations pourraient, soixante-dix ans plus tard, servir de moteur à un système d’intelligence artificielle capable de simuler l’évolution d’un environnement physique. C’est pourtant exactement ce que propose FluidWorld : remplacer le mécanisme d’attention des Transformers — la brique fondamentale de ChatGPT, Gemini et de la quasi-totalité des agents IA modernes — par la physique des fluides chimiques réactifs. Non par caprice esthétique, mais parce qu’un argument arithmétique précis l’exige.
Un carré qui coûte cher
Le mécanisme d’attention, introduit par Vaswani et al. en 2017 dans l’article Attention Is All You Need, repose sur une idée élégante. Lorsqu’un modèle traite une séquence de N éléments — mots d’une phrase, blocs d’une image, états successifs d’un environnement —, il calcule, pour chaque élément, un score de pertinence par rapport à tous les autres. Ce mécanisme permet de saisir des dépendances à longue distance : dans la phrase « Le pianiste que sa mère avait encouragé depuis l’enfance joua », l’accord entre « pianiste » et « joua » exige de sauter plusieurs mots ; l’auto-attention s’en charge sans difficulté.
Le problème est strictement arithmétique. Le nombre de comparaisons à effectuer est N × N, soit N². En notation algorithmique : complexité O(N²). Doubler la longueur de la séquence ne double pas le coût de calcul — il le quadruple. Pour N = 1 000, on effectue un million d’opérations ; pour N = 10 000, cent millions. C’est l’équivalent d’une facture de téléphone dont le montant ne doublerait pas si vous doubliez votre consommation, mais l’élèverait au carré : confortable pour les petits usages, ruineux pour les grands.
Pour des séquences courtes, cette contrainte reste gérable. Elle devient prohibitive pour une catégorie d’architectures que les chercheurs étudient de plus en plus intensément : les world models.
Jouer les coups dans sa tête
Un world model — « modèle prédictif du monde » — est un système capable de simuler mentalement l’évolution probable de son environnement sans avoir à y interagir physiquement à chaque étape. L’analogie la plus juste est celle du joueur d’échecs qui, avant de déplacer une pièce, explore mentalement plusieurs lignes de jeu sans toucher l’échiquier. Il simule, évalue, puis agit.
Cette capacité est précieuse pour les agents autonomes : au lieu d’apprendre uniquement par essais et erreurs dans le monde réel — coûteux, lent, parfois dangereux —, un agent doté d’un world model peut s’entraîner sur des trajectoires imaginées. Des architectures comme DreamerV3 ou TD-MPC2 reposent sur ce principe. Or, un world model doit traiter de longues séquences d’observations spatiales : des images successives d’un environnement, des configurations physiques évoluant dans le temps. C’est exactement là que le goulot d’étranglement quadratique cesse d’être théorique.
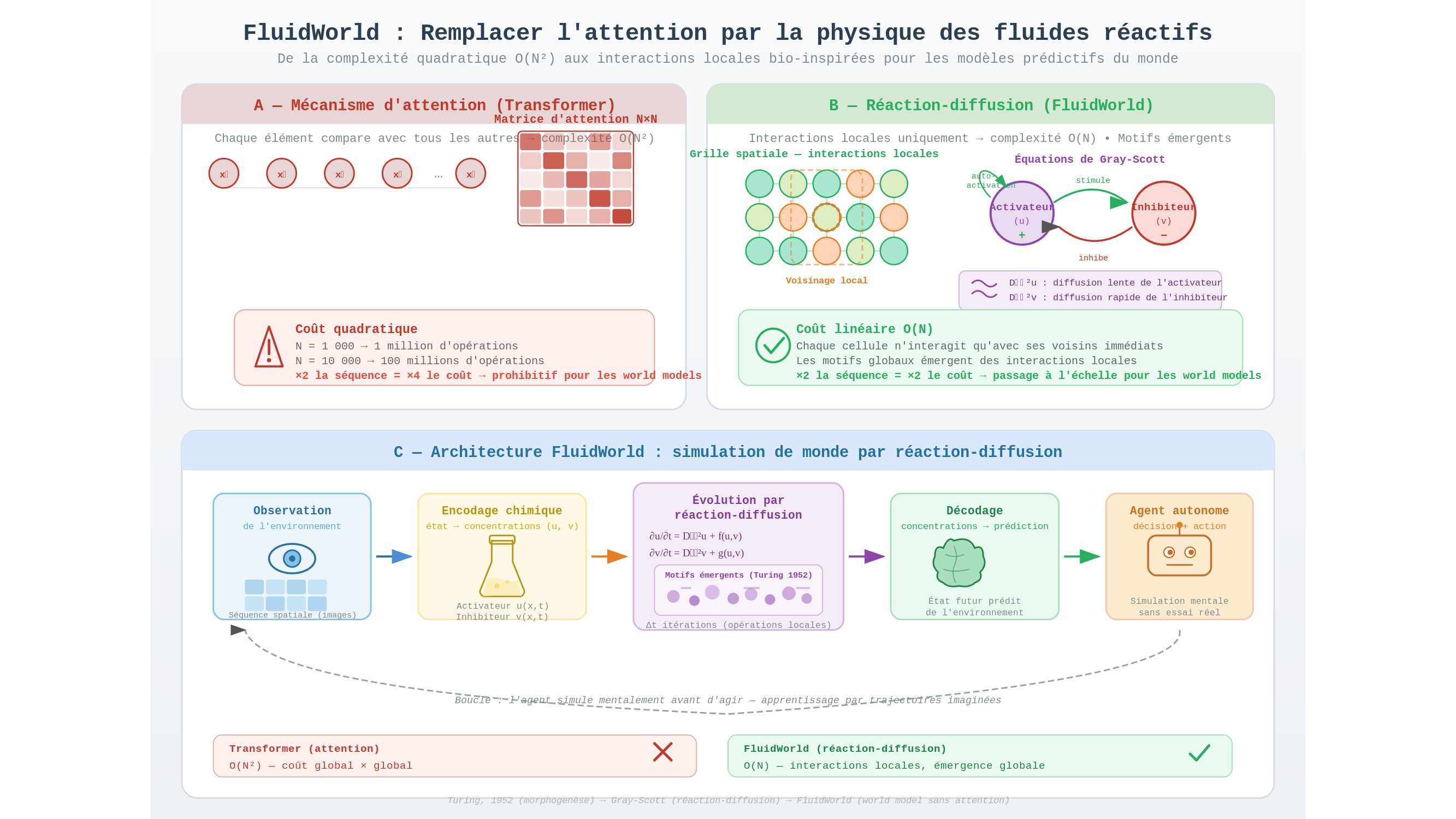
Ce que le léopard sait faire sans calculer
Les équations de réaction-diffusion décrivent comment deux substances chimiques — un activateur et un inhibiteur — interagissent et se propagent dans un milieu. Un activateur stimule sa propre production et celle de l’inhibiteur ; l’inhibiteur diffuse plus vite et freine l’activateur. De ce simple jeu de forces locales émergent, selon les paramètres choisis, des rayures régulières, des taches hexagonales, des spirales tournantes. Les équations de Gray-Scott, variante particulièrement étudiée, reproduisent numériquement des structures impossibles à distinguer de celles que l’on observe sur le pelage du guépard.
Ce qui rend ce substrat attractif du point de vue computationnel est précisément sa localité : dans un système de réaction-diffusion, chaque point n’interagit qu’avec ses voisins immédiats. L’information se propage comme une vague sur un lac, par cercles concentriques, plutôt que d’être transmise instantanément à tous les points du plan. En termes de coût, cette localité garantit une complexité linéaire en N : doubler la séquence double le coût, et rien de plus.
Il y a ici un argument plus profond que la seule efficacité computationnelle. Les équations de réaction-diffusion possèdent un biais inductif spatial naturel — elles sont structurellement adaptées à représenter des phénomènes qui se déroulent dans l’espace physique, où ce qui arrive en un point dépend en priorité de ce qui arrive à ses voisins. Un environnement réel obéit à cette contrainte. L’auto-attention, elle, l’ignore délibérément : pour elle, deux éléments distants de mille pas sont aussi proches que deux éléments adjacents.
Ce que la preuve de concept démontre — et ce qu’elle ne démontre pas
Il faut être précis sur ce que FluidWorld accomplit réellement. L’article est explicitement présenté comme une preuve de concept. Il ne prétend pas surpasser DreamerV3 ni atteindre l’état de l’art sur les benchmarks standards. Son ambition est plus modeste — et philosophiquement plus importante : démontrer la viabilité d’un substrat alternatif. Montrer qu’un world model peut fonctionner sans auto-attention, que l’absence d’attention n’est pas rédhibitoire par principe.
En logique mathématique, on distingue soigneusement une condition suffisante d’une condition nécessaire. Que l’attention soit suffisante pour construire des world models performants, c’est établi depuis plusieurs années et étayé empiriquement. Que cette condition soit également nécessaire, c’est une affirmation bien plus forte — et c’est précisément cette affirmation que FluidWorld commence à fragiliser.
Plusieurs zones d’ombre subsistent. La complexité linéaire est une propriété théoriquement séduisante ; reste à démontrer empiriquement que les performances suivent sur des tâches complexes à haute dimensionnalité. Le biais inductif spatial qui fait la force des équations de réaction-diffusion dans les environnements locaux pourrait constituer leur faiblesse dans les tâches requérant des dépendances à très longue distance — exactement ce pour quoi l’attention a été conçue. Un world model chargé de planifier sur un horizon de plusieurs centaines de pas pourrait souffrir d’une propagation trop lente de l’information. Enfin, le DOI fourni (10.3917/gmp.pr1.0012) ne permet pas, à ce stade, de confirmer l’accès public au code source — une limitation réelle pour la reproductibilité.
Une invitation ancienne de trente millions d’années
Il faut replacer cette question dans son contexte plus large. Les choix architecturaux qui dominent l’IA actuelle ne résultent pas d’une démonstration théorique qu’ils sont optimaux. Ils reflètent une trajectoire historique : des succès empiriques successifs, une concentration considérable des ressources de calcul, et une inertie technologique que les économistes appellent parfois lock-in. Il n’existe aucune preuve que l’attention soit la seule voie, ni même la meilleure — seulement la preuve qu’elle fonctionne remarquablement bien sur les tâches pour lesquelles on l’a massivement éprouvée.
Ce n’est pas la première fois que le champ connaît ce type de moment. Pendant des décennies, les réseaux de neurones artificiels coexistaient avec des approches alternatives — réseaux bayésiens, machines à vecteurs de support, systèmes à base de règles —, avant que la convergence de données massives et de puissance de calcul ne fasse basculer presque tout le champ vers les architectures profondes, en quelques années. Rien ne garantit que le même type de transition ne puisse se reproduire.
Mais la vraie question que laisse ouverte FluidWorld n’est pas « les équations de réaction-diffusion battront-elles les Transformers ? ». Elle est : combien d’autres substrats computationnels, que nous n’avons pas encore sérieusement explorés, la nature a-t-elle déjà inventés et patiemment affinés ? Le léopard porte sur lui une réponse vieille de trente millions d’années. Nous commençons à peine à lui poser la bonne question.
À lire aussi sur Émergence :
- Le roi boiteux : pourquoi Stable Diffusion XL règne encore sur un trône qu’il ne mérite plus tout à fait