
Il y a quelque chose de troublant dans l’histoire que voici. En 2020, GPT-3 impressionne le monde entier — 175 milliards de paramètres, des textes d’une cohérence déconcertante, des performances qui semblent annoncer une rupture. Deux ans plus tard, une équipe de DeepMind publie une étude qui jette une lumière nouvelle, et légèrement cruelle, sur cette prouesse : ce modèle qui avait sidéré les spécialistes avait été, selon les critères de Jordan Hoffmann et ses collègues, entraîné à moins de dix pour cent de son potentiel optimal. Pas en raison d’une négligence, ni d’un manque de ressources. Mais parce que la question que l’on se posait était mal formulée.
La question mal posée était celle-ci : « quelle est la taille maximale du modèle que nous pouvons entraîner avec notre budget de calcul ? » La question correcte aurait été : « comment répartir ce budget entre la taille du modèle et la quantité de données d’entraînement ? » Ce glissement — d’une question de grandeur à une question de proportion — est tout sauf anecdotique. Il touche à ce qu’on appelle, dans ce domaine, les « lois d’échelle ».
Que recouvre exactement ce mot de « loi » ? En physique, une loi décrit une régularité universelle, indépendante du contexte, valide en tout lieu et en tout temps — la loi de la gravitation, la loi d’Ohm. Les « lois d’échelle » qui gouvernent l’entraînement des grands modèles de langage (large language models, dans la terminologie anglaise) n’ont pas cette ambition. Ce sont des régularités empiriques, observées dans un régime de calcul particulier, dont rien ne garantit qu’elles se prolongent indéfiniment. Elles ressemblent moins aux lois de Newton qu’aux lois allométriques de la biologie — ces relations entre la taille d’un animal et son métabolisme, qui tiennent sur plusieurs décades de variation mais que personne ne prétend universelles. Le mot « loi » flatte ici notre désir de symétrie ; il ne faudrait pas en abuser.
La régularité en question, telle que Jordan Hoffmann et ses collègues l’ont précisée en 2022, peut s’énoncer simplement : pour un budget de calcul fixé, la performance optimale d’un modèle s’obtient en entraînant un modèle environ deux fois moins grand que ce que suggérait la pratique alors dominante, mais sur deux fois plus de données. Autrement dit, la course à la taille — construire toujours plus de paramètres — s’était faite au détriment de l’alimentation. C’est un peu comme si, dans l’effort de construire une bibliothèque immense, on avait négligé de la remplir : on obtenait des rayonnages somptueux et des étagères à moitié vides.
Le modèle issu de cette étude, baptisé Chinchilla — un nom qui détonne dans la littérature scientifique et qui a dû faire sourire plus d’un lecteur —, illustrait la thèse de manière saisissante : avec quatre fois moins de paramètres que son concurrent Gopher, et entraîné sur quatre fois plus de données, il obtenait de meilleures performances sur la quasi-totalité des critères d’évaluation. La leçon semblait claire. Elle l’était peut-être trop.
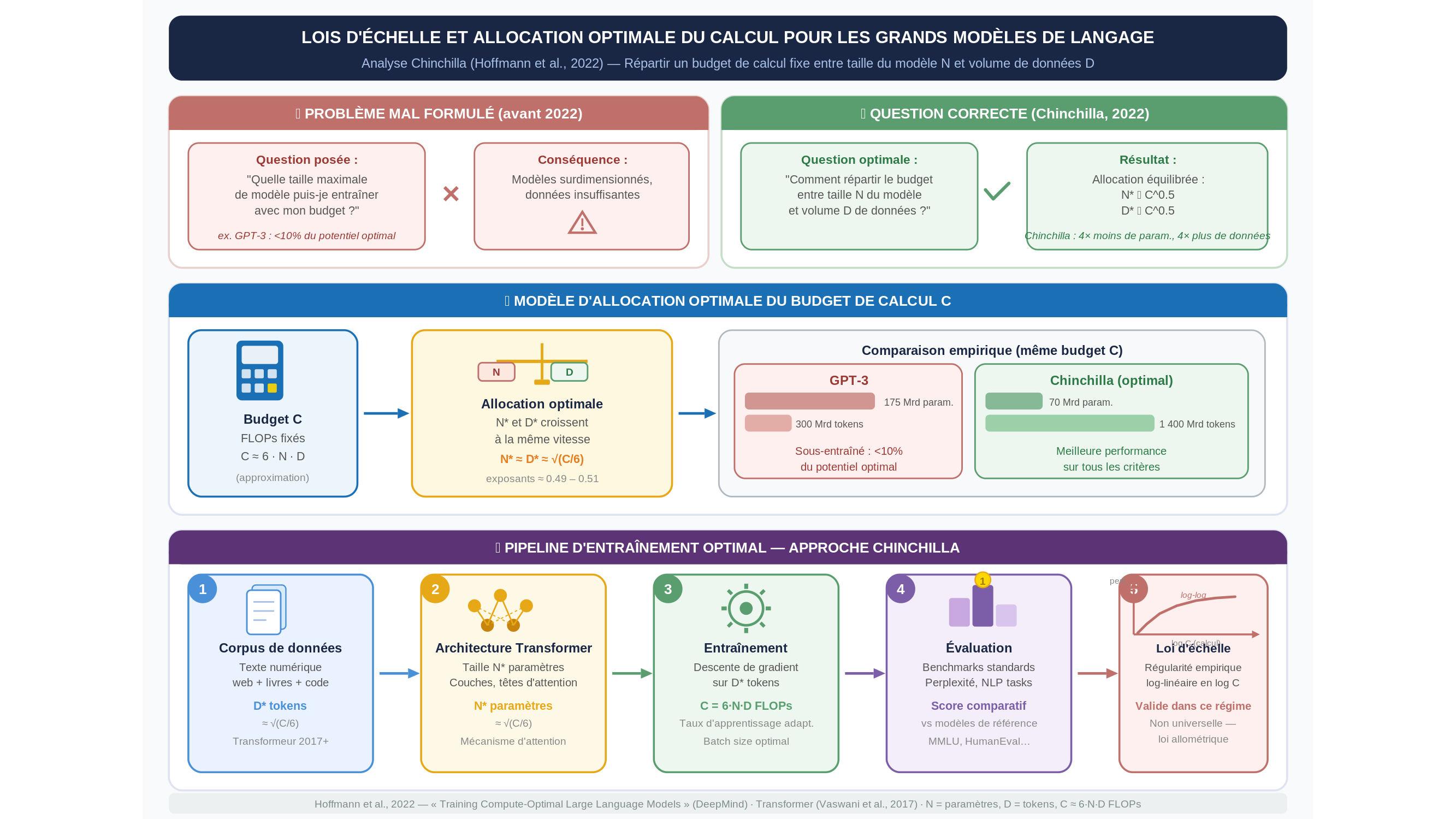
Car il faut nuancer. Ces résultats ont été obtenus dans des conditions très spécifiques — un budget de calcul donné, des architectures de type transformeur (architecture à mécanisme d’attention, développée à partir de 2017), des données issues du texte numérique disponible sur l’internet. Extrapoler ces lois hors de ce régime revient à prédire le comportement d’un pont à partir d’expériences menées sur des allumettes. Les chercheurs qui travaillent sur ces questions le savent ; ce sont souvent les commentateurs qui l’oublient.
Jusqu’en 2023, tout ce travail d’optimisation restait jalousement gardé. Non par obscurantisme — les laboratoires qui menaient ces recherches publiaient abondamment sur les architectures, les techniques d’alignement, les critères d’évaluation. Mais les recettes concrètes d’entraînement — la taille des lots de données, la façon dont le taux d’ajustement des paramètres décroît au fil des étapes, le traitement de la diversité linguistique dans les corpus — résultaient d’années d’expérimentations coûteuses. Les partager revenait à offrir un avantage compétitif considérable.
La rupture est venue de Meta AI. En publiant la série LLaMA en 2023 avec une documentation détaillée de son protocole d’entraînement, le laboratoire a rompu cette règle implicite. D’autres ont suivi : Falcon, développé par le Technology Innovation Institute d’Abou Dhabi ; Mistral AI, fondée à Paris ; EleutherAI, consortium international ayant constitué le corpus Pile — terme anglais désignant une agrégation hétérogène de textes publics, que l’on pourrait rendre par « amas » ou « empilement ». Ces publications ont rendu accessibles, pour la première fois, le détail des choix techniques qui transforment une architecture théorique en un système fonctionnel.
Ce mouvement d’ouverture mérite qu’on s’y arrête, sans naïveté. Il signifie que des équipes disposant de ressources bien inférieures peuvent désormais s’appuyer sur ces protocoles pour entraîner des modèles compétitifs — ce qui s’est effectivement produit. Mais il ne résout pas la question de fond : entraîner un modèle de soixante-dix milliards de paramètres sur mille milliards de mots requiert, selon les estimations par ordre de grandeur couramment admises, de l’ordre de 10²³ opérations arithmétiques. Pour donner une idée de cette magnitude sans recourir aux superlatifs : un centre de données équipé de mille processeurs graphiques haut de gamme travaillant en parallèle y consacre plusieurs semaines. Patterson et ses collègues avaient estimé dès 2021 que l’empreinte carbone d’un tel entraînement pouvait dépasser celle de centaines de vols transatlantiques — un coût environnemental que la mise à disposition des recettes ne réduit pas. L’accessibilité des protocoles ne démocratise pas l’accès aux infrastructures. Elle offre la carte mais pas le territoire.
Une autre question, plus discrète, mérite d’être posée. Les lois d’échelle optimisent la performance selon un critère bien précis : la perplexité, c’est-à-dire, pour simplifier, la capacité du modèle à prédire le mot suivant dans une séquence donnée. Ce critère a l’avantage d’être mesurable, stable, facile à automatiser. Mais il n’est pas neutre : un modèle « optimal » au sens de Chinchilla est un modèle dont les paramètres sont ajustés pour mieux reproduire le texte humain disponible sur l’internet — avec tout ce que cela implique en termes de biais, de surreprésentation de certaines langues, de certains registres, de certaines visions du monde. L’optimum technique est toujours un optimum par rapport à une valeur donnée ; cette valeur, on l’a peut-être choisie trop vite.
La recette est désormais en libre accès. Reste à savoir ce qu’on cuisine, et pourquoi.
À lire aussi sur Mémorabilité :
- Tâches d’induction, d’analogie et de causalité : des écarts de performance marqués dans les grands modèles de langue
- Sous pression, les LLMs abandonnent-ils leurs preuves ? Une étude sur 19 modèles
- Cybersécurité et IA : l’apprentissage contrastif pour des modèles qui tiennent leurs promesses en production
Sources
- Hoffmann, J. et al. (2022). Training Compute-Optimal Large Language Models. arXiv:2203.15556
- Patterson, D. et al. (2021). Carbon Emissions and Large Neural Network Training. arXiv:2104.10350
- Touvron, H. et al. (2023). LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971


