
Le problème des coordonnées : pourquoi les réseaux de neurones ne peuvent pas mémoriser sans se perdre
Article Émergence — 26 mars 2026
Prenons un exemple aussi simple que brutal. On entraîne un réseau de neurones à reconnaître des chats — disons avec une précision de 94 %. On l’entraîne ensuite à reconnaître des chiens. Au terme de ce second entraînement, la précision sur les chiens atteint 91 %. Parfait. Mais si l’on reteste le réseau sur les chats, sa précision est retombée aux alentours de 10 % — soit le niveau d’un classifieur qui répondrait au hasard parmi dix catégories. Les paramètres qui codaient la reconnaissance des chats ont été écrasés par ceux qui codaient celle des chiens. Pas dégradés — écrasés. Ce phénomène s’appelle l’oubli catastrophique (catastrophic forgetting), et il est documenté depuis 1989, date à laquelle Michael McCloskey et Neal Cohen l’ont caractérisé avec précision. Trente-cinq ans et des milliers d’articles plus tard, il n’est toujours pas résolu.
Ce n’est pas une curiosité de laboratoire sans conséquences pratiques. Tout système qui doit apprendre en continu — un robot en interaction avec un environnement changeant, un assistant médical qui intègre de nouvelles recommandations sans oublier les anciennes, un système de contrôle industriel — se heurte à cet obstacle fondamental. L’apprentissage profond (deep learning) actuel est exceptionnel pour apprendre une tâche à partir d’un corpus fixe. Il est structurellement mal adapté à l’apprentissage séquentiel de plusieurs tâches successives.
Deux grandes familles de solutions ont émergé depuis 2017. La première, portée par une équipe de DeepMind menée par James Kirkpatrick, repose sur ce qu’on appelle la consolidation élastique des poids — Elastic Weight Consolidation (EWC) dans la littérature. L’idée est d’estimer, pour chaque tâche déjà apprise, quels paramètres du réseau lui sont les plus essentiels, puis de les protéger lors des apprentissages suivants en leur imposant une résistance au changement proportionnelle à leur importance. L’analogie est celle d’amortisseurs : les connexions cruciales se déforment moins, l’oubli est freiné. La méthode fonctionne — partiellement. Elle exige de stocker pour chaque tâche une estimation de l’importance des paramètres, ce qui représente un surcoût mémoire proportionnel au nombre de tâches. Et l’oubli n’est jamais totalement supprimé, seulement ralenti.
La seconde famille, illustrée par les réseaux neuronaux progressifs proposés par Andrei Rusu et ses collègues — également chez DeepMind — contourne le problème autrement : plutôt que de modifier les connexions existantes, on les gèle et on ajoute de nouveaux modules à chaque nouvelle tâche. La mémoire des tâches passées est parfaitement préservée, puisqu’on n’y touche plus. Mais la taille du réseau croît linéairement avec le nombre de tâches : pour un système devant en apprendre cent, la structure devient rapidement ingérable.
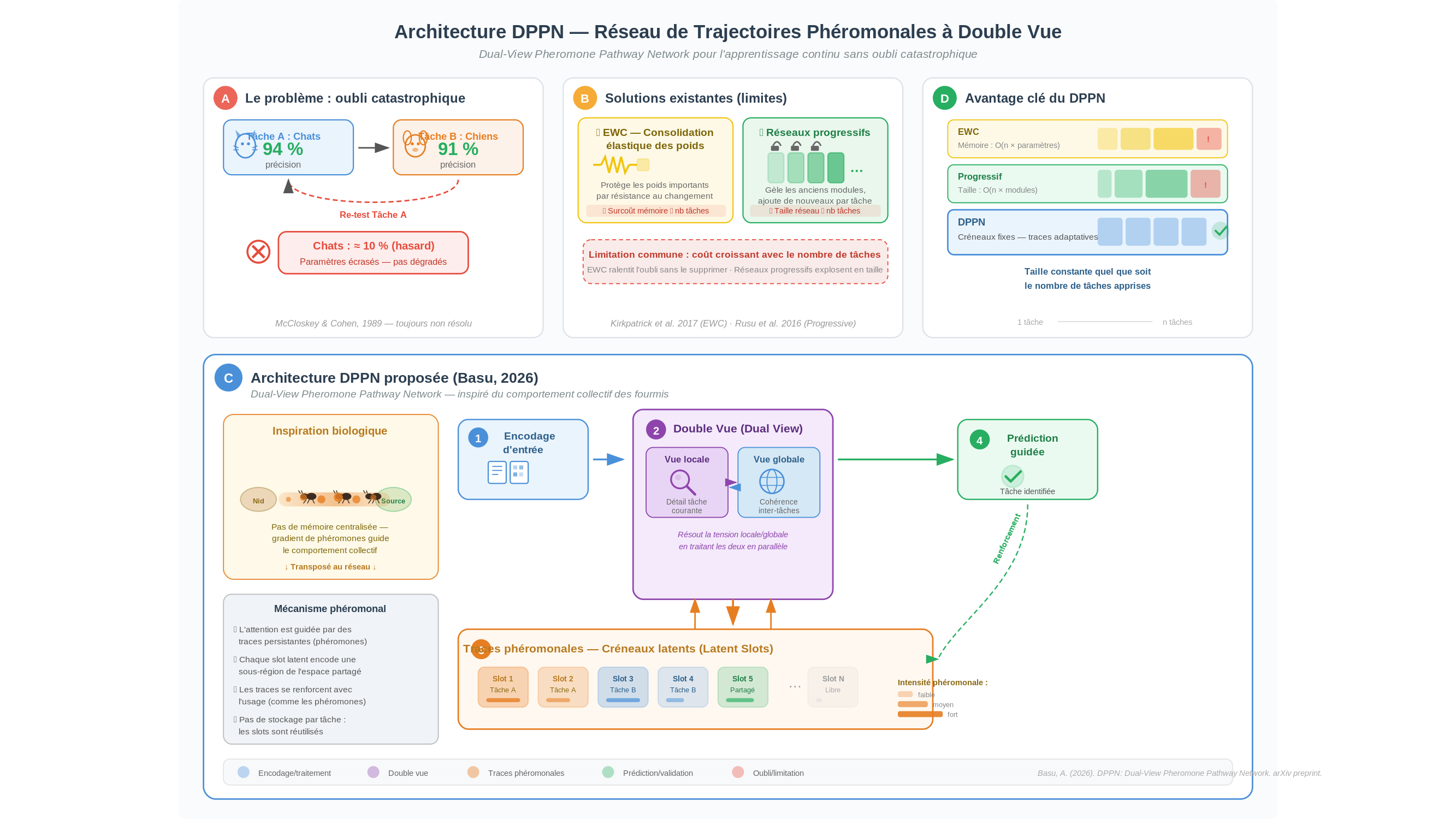
C’est dans ce paysage bien balisé qu’un article déposé en mars 2026 sur arXiv par Abhinaba Basu — chercheur apparemment isolé, sans co-auteurs ni affiliation institutionnelle identifiable dans le document — tente une voie différente. L’architecture proposée, baptisée DPPN (Dual-View Pheromone Pathway Network, réseau de trajectoires phéromonales à double vue), s’inspire du comportement des fourmis. Une colonie qui cherche de la nourriture ne dispose d’aucune mémoire collective centralisée : chaque individu suit le gradient de concentration des phéromones déposées par ses congénères, et l’ensemble du groupe converge vers une solution efficace sans que personne n’ait jamais la vue d’ensemble. Basu transpose ce principe à la mémoire interne du réseau : des « traces » persistantes, analogues aux phéromones, guident l’attention à travers des emplacements discrets de l’espace de représentation — les latent slots, les créneaux latents — maintenant une cohérence structurelle d’une tâche à l’autre.
L’idée est séduisante. Mais l’apport le plus solide de ce travail n’est pas l’architecture elle-même — c’est le diagnostic qu’elle permet de formuler. À travers cinq expériences successivement affinées (jusqu’à dix répétitions par condition, cinq variantes d’architecture testées, quatre cibles de transfert), Basu identifie ce qu’il nomme le « problème du système de coordonnées » : pour que la mémoire persistante fonctionne, il faut un système de repères stable qui permette au réseau de situer ses nouvelles représentations par rapport aux anciennes. Or, tout système de coordonnées appris conjointement avec le modèle est, par construction, instable — il évolue avec l’apprentissage, et cette évolution corrompt précisément la stabilité recherchée.
On peut montrer que ce résultat est, en un sens, inévitable. Il s’apparente à ce qu’un géographe rencontrerait s’il tentait de dresser une carte fiable d’un territoire dont le relief se modifie en permanence : non pas par manque de méthode, mais parce que la carte et le territoire se transforment ensemble. Si les coordonnées sont apprises par le réseau, elles dérivent avec lui. Si elles sont fixées a priori, elles doivent être choisies pour correspondre à la structure du problème — et ce choix n’est pas trivial, puisque la structure du problème est précisément ce qu’on cherche à apprendre.
Ce résultat négatif — au sens strict du terme : une impossibilité démontrée conditionnellement — est peut-être la contribution la plus précieuse de l’article. Il reformule le problème de l’apprentissage continu en termes plus fondamentaux que ne le faisait la littérature antérieure, et il suggère que les approches comme EWC ou les réseaux progressifs ne traitent que des symptômes, sans toucher à la cause structurelle.
Cela dit, la prudence s’impose avant d’aller plus loin. L’article ne présente pas de comparaison directe avec les méthodes de référence sur les bancs d’essai standardisés qu’utilise la communauté — notamment les suites Split-CIFAR et Permuted-MNIST, qui permettent de situer les performances de manière objective par rapport à l’état de l’art. Sans cela, il est impossible de savoir si DPPN fait mieux, aussi bien, ou moins bien qu’EWC ou que les approches fondées sur la répétition des données passées (experience replay). L’architecture est décrite, les expériences sont menées avec soin, mais la comparaison qui permettrait de trancher sur l’efficacité pratique fait défaut. Ce n’est pas nécessairement un défaut rédhibitoire — les travaux théoriques n’ont pas toujours à démontrer une supériorité empirique — mais c’est une limite que le lecteur doit avoir clairement en tête.
On notera également que l’inspiration phéromonale, si elle est intellectuellement cohérente, n’est pas inédite. L’optimisation par colonies de fourmis (Ant Colony Optimization) proposée par Marco Dorigo en 1992 est une méthode bien établie, et plusieurs travaux ont tenté d’en adapter les principes à l’apprentissage automatique. Ce que Basu apporte de nouveau, ce n’est pas l’analogie biologique en elle-même, mais son application au problème spécifique de la mémoire structurelle persistante, et la clarification conceptuelle sur les coordonnées qui en découle.
Enfin, il faut souligner qu’un article sans co-auteurs ni relecture institutionnelle visible n’a pas encore bénéficié du regard critique d’une communauté élargie. Cela ne le disqualifie pas — plusieurs travaux marquants de l’histoire des sciences sont nés de chercheurs isolés —, mais cela impose une réserve supplémentaire sur les conclusions les plus ambitieuses.
Reste une question que l’article soulève sans la résoudre, et qui mérite d’être formulée clairement : si aucun système de coordonnées appris ne peut être stable, existe-t-il un système de coordonnées innés — inscrit dans l’architecture elle-même avant tout apprentissage — qui serait suffisamment général pour servir de référentiel à n’importe quelle tâche ? C’est, d’une certaine manière, la question que pose l’évolution biologique pour les cerveaux animaux : certaines structures anatomiques sont présentes avant toute expérience, et c’est sur elles que s’appuie l’apprentissage. La réponse pour les réseaux artificiels reste ouverte. Mais la question est désormais posée avec une netteté qu’elle n’avait pas auparavant.
Figures originales du paper


Sources
- Abhinaba Basu, The Coordinate System Problem in Persistent Structural Memory for Neural Architectures, arXiv, mars 2026. [Préimpression non révisée par les pairs — seule source documentaire fournie pour cet article]
Travaux cités dans le texte à titre de contexte historique et scientifique : McCloskey & Cohen (1989) sur l’oubli catastrophique ; Kirkpatrick et al. (2017) sur EWC (Overcoming catastrophic forgetting in neural networks, PNAS) ; Rusu et al. (2016) sur les réseaux neuronaux progressifs (arXiv) ; Dorigo (1992) sur l’optimisation par colonies de fourmis. Ces références sont des publications établies et vérifiables, citées sans reproduction de leurs identifiants pour ne pas risquer d’erreur sur les DOI ou numéros d’arXiv exacts.