
La pensée visible : ce que DeepSeek-R1 nous apprend sur le raisonnement
En une seule nuit de janvier 2025, des centaines de milliards de dollars se sont évaporés des marchés financiers américains — Nvidia, à elle seule, voyait fondre près de 600 milliards de capitalisation. Non à cause d’un séisme géopolitique ni d’une faillite bancaire, mais à cause d’un article de recherche publié sur internet par une équipe chinoise peu connue du grand public. Ce n’est pas le chiffre qui mérite réflexion — les marchés ont leurs propres irrationnalités —, mais ce qu’il trahit : une certitude s’était insinuée dans les esprits au point d’être convertie en valeur boursière, la certitude que l’intelligence artificielle de pointe appartenait, et appartiendrait durablement, à quelques laboratoires occidentaux bien identifiés. Ce modèle s’appelle DeepSeek-R1. Ce qui le rend philosophiquement intéressant n’est pas qu’il ait « dépassé » ses concurrents — cette affirmation, dont la presse a abusé, ne signifie à peu près rien tant les critères d’évaluation sont disputés —, mais qu’il expose quelque chose que l’on préférait peut-être ne pas voir.
Ce quelque chose commence par une balise.
Dans les démonstrations publiques de DeepSeek-R1, on observe ces marqueurs <think>...</think> qui encadrent un long soliloque : reconsidération d’hypothèses, détection d’erreurs internes, correction de trajectoire. Ce monologue est lisible. Le modèle pense, pour dire, à voix haute avant de conclure — non parce qu’on le lui a imposé comme une règle de présentation, mais parce que cette stratégie s’est révélée, à l’entraînement, statistiquement gagnante. On peut regarder ce fait de deux manières. La première : c’est une interface, une mise en scène du calcul, qui ne nous apprend rien sur ce qu’est « penser », pas plus que la fumée d’une locomotive ne nous renseigne sur la thermodynamique. La deuxième : cette trace, en rendant le raisonnement partiellement inspectable, déplace la question philosophique — non plus « les machines pensent-elles ? », mais « à quoi ressemble ce que nous appelons penser, quand on peut en lire le déroulement ? ». Ces deux lectures ne sont pas conciliables. C’est pourquoi il faut les garder toutes les deux ouvertes.
L’argent, lui, révèle une autre structure — non plus philosophique, mais organisationnelle.
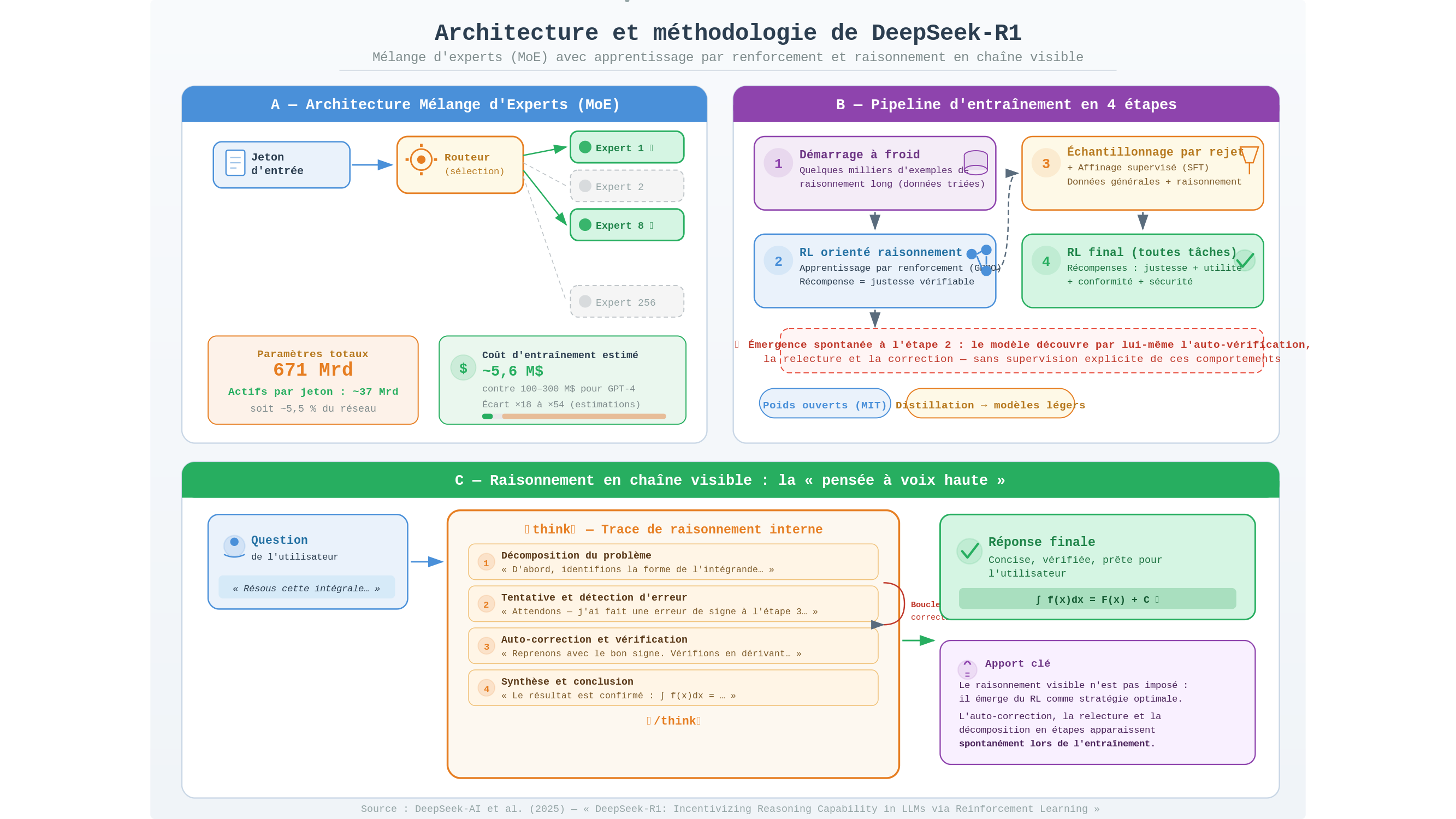
On estimait jusqu’ici que seuls quelques laboratoires disposaient des ressources nécessaires pour entraîner des modèles de ce niveau. L’entraînement de GPT-4 aurait coûté, selon les estimations les plus répandues, entre 100 et 300 millions de dollars. DeepSeek affirme avoir entraîné R1 pour environ 5,6 millions. Il faut ici marquer une pause : ce chiffre ne peut être vérifié indépendamment, et il ne tient probablement pas compte de tous les coûts — recherche amont, infrastructure, tentatives avortées. Il reste à prendre avec prudence. Mais même en l’admettant sous-estimé d’un facteur trois, l’écart demeurerait saisissant. Ce que cela révèle n’est pas un secret de fabrication, mais une vérité inconfortable : les barrières à l’entrée dans la course aux grandes intelligences artificielles étaient peut-être davantage organisationnelles et stratégiques que strictement financières. Ce n’est pas tout à fait la même chose.
L’architecture du modèle prolonge cette logique d’efficacité jusqu’à ses conséquences les plus radicales.
DeepSeek-R1 repose sur une structure dite « mélange d’experts » — Mixture of Experts, ou MoE dans la terminologie du domaine. Plutôt que de mobiliser la totalité du réseau pour chaque calcul — ce qui serait analogue à convoquer l’intégralité du personnel d’un hôpital autour de chaque consultation, du directeur général à l’aide-soignant, pour répondre à la moindre question d’un patient —, le modèle ne sollicite à chaque instant qu’une fraction de ses composantes. Sur les 671 milliards de paramètres qui le constituent au total, seuls environ 37 milliards sont actifs à chaque traitement. Cette sélectivité réduit considérablement le coût d’« inférence » — c’est-à-dire le coût de fonctionnement une fois le modèle formé — sans sacrifier les performances globales (source : arXiv:2501.12948). L’efficacité n’est pas ici une vertu morale ; c’est une contrainte architecturale qui oblige les concurrents à réévaluer leurs propres choix.
Mais c’est la nature de l’entraînement qui mérite le plus d’attention philosophique.
DeepSeek-R1 a été formé principalement par apprentissage par renforcement pur — sans supervision humaine massive, sans armée d’annotateurs chargés de qualifier les bonnes et mauvaises réponses. L’algorithme utilisé, le GRPO (Group Relative Policy Optimization), fonctionne selon un principe d’une élégance presque brutale : le modèle génère plusieurs réponses candidates à un problème donné, et celles qui aboutissent à la bonne solution finale sont récompensées. Pas d’intermédiaire humain, pas de modèle de récompense distinct — un signal binaire : correct ou non. On reconnaît là la structure de tout apprentissage par essais et erreurs, que les théoriciens du comportement ont étudiée chez les animaux bien avant qu’elle soit transposée aux machines. La différence d’échelle est vertigineuse : des millions d’itérations par heure, sur des problèmes de mathématiques ou de logique formelle.
Ce qui s’est produit alors n’était pas anticipé.
Une version intermédiaire du modèle, soumise à ce régime de renforcement pur avant toute distillation, a développé spontanément des comportements que personne n’avait explicitement programmés : reconsidération d’hypothèses en cours de raisonnement, détection d’erreurs internes, vérification croisée des résultats. Le modèle avait appris à douter — non parce qu’on le lui avait enseigné, mais parce que douter s’était révélé, dans la pratique, une stratégie gagnante. Ce phénomène porte dans la littérature spécialisée le nom d’« émergence » : l’apparition de capacités non anticipées lors de l’entraînement. Le terme est commode, mais il risque de masquer notre ignorance. Dire qu’une capacité est « émergente » revient souvent à dire qu’on ne sait pas encore comment elle est apparue. Et c’est précisément là que la question philosophique se réinstalle : jusqu’où peut aller cette émergence, et que recouvre exactement le mot « raisonnement » quand on l’applique à un système qui n’a, au sens strict, jamais rien vécu ?
Il faut ici résister à la tentation de la réponse facile — dans les deux sens.
L’étymologie du terme « raisonnement » — du latin ratio, qui désigne à la fois le calcul et la raison — nous renvoie précisément à l’ambiguïté que nous cherchions à lever. Ce que DeepSeek-R1 produit ressemble fonctionnellement à du raisonnement, se comporte comme du raisonnement sur les épreuves standardisées — il atteint environ 79,8 % de réussite sur le concours mathématique AIME 2024, contre 79,2 % pour le modèle o1 d’OpenAI —, mais si cela constitue ou non du raisonnement au sens philosophique du terme, nul ne peut l’affirmer avec certitude. Ces épreuves méritent d’ailleurs d’être interrogées : elles ont été conçues pour évaluer des capacités humaines, et à mesure que les modèles atteignent des scores proches du maximum, deux risques se font jour. Le premier est celui de la contamination des données d’entraînement — le modèle aurait pu rencontrer ces problèmes durant son apprentissage. Le second, plus fondamental, est celui d’une dissociation entre performance sur le test et capacité réelle dans des contextes inédits. Il est encore trop tôt pour affirmer que DeepSeek-R1 « raisonne mieux » que ses concurrents dans la généralité des situations.
La question géopolitique, elle, est peut-être la moins ambiguë — quoique la moins philosophiquement intéressante.
DeepSeek publie ses poids sous licence MIT, là où OpenAI, Google et Anthropic maintiennent leurs modèles les plus avancés fermés, accessibles seulement via des interfaces payantes. Ce geste d’ouverture n’est pas dénué d’arrière-pensées : en rendant le modèle librement disponible, DeepSeek s’assure une adoption mondiale rapide — plus d’un million et demi de téléchargements recensés sur la plateforme HuggingFace peu après la publication — et contraint implicitement ses concurrents à justifier leurs politiques de fermeture. L’ouverture du code comme instrument de puissance. Six versions allégées ont été publiées simultanément, de 1,5 à 70 milliards de paramètres, permettant à quiconque disposant d’un ordinateur relativement récent d’exécuter localement un modèle de niveau comparable à ceux qui nécessitaient hier des centres de données entiers. Il serait néanmoins naïf d’appeler cela « démocratisation » sans réserve. Ce que l’ouverture des poids distribue, c’est le droit d’utiliser — non celui de reproduire, d’améliorer souverainement, ni même de comprendre ce qui s’est réellement passé durant l’entraînement. DeepSeek ne publie pas l’intégralité de ses données ni le détail de ses choix de prétraitement : la transparence a ici ses limites précises, et la confiance accordée à un modèle dont on ignore les biais potentiels reste un pari.
Ce que DeepSeek-R1 a peut-être accompli de plus durable, c’est de déplacer silencieusement les termes du débat. On discutait de la course aux paramètres — qui aurait le modèle le plus grand, le budget le plus élevé, la puissance de calcul la plus massive. On discute désormais de la course à l’efficacité : qui saura obtenir le plus avec le moins. Ce renversement des critères rappelle ce qui s’est produit à plusieurs reprises dans l’histoire des techniques, quand une contrainte imposée de l’extérieur — manque de ressources, embargo, isolation — a conduit à des solutions que l’abondance n’aurait peut-être jamais fait chercher.
Reste la question des balises <think> — ce monologue que le modèle expose avant de conclure. Si forcer un système à développer explicitement son raisonnement intermédiaire améliore réellement ses performances — ce que les chiffres semblent indiquer —, alors c’est peut-être que la pensée, humaine ou artificielle, n’est pas un processus qui précède son expression : elle est, pour une part indéterminée, constituée par elle. La mise en forme d’une pensée en modifierait le contenu. Les philosophes du langage l’ont dit de l’écriture depuis des siècles. Que cela vaille aussi pour des architectures entraînées par gradient descendant sur des milliards de tokens, voilà qui n’avait pas été sérieusement envisagé.
D’où vient cette capacité ? Comment l’émergence du doute peut-elle résulter d’un signal binaire ? Et si la pensée visible est plus efficace que la pensée muette, cela nous dit-il quelque chose sur la pensée — ou seulement sur l’efficacité ? Nul ne le sait encore.