Quand l’IA apprend à ne plus répéter ses erreurs : le pari risqué de Microsoft
Imaginez un chirurgien qui, au terme de chaque intervention, oublierait tout ce qui vient de se passer. Ni les complications rencontrées, ni les gestes qui ont échoué, ni ceux qui ont sauvé la situation. Il reprendrait le lendemain exactement comme la veille — avec les mêmes angles morts, les mêmes réflexes défaillants. C’est, peu ou prou, le problème que les agents d’intelligence artificielle posent depuis leur apparition : capables de performances impressionnantes sur des tâches isolées, ils n’accumulent pas d’expérience au sens où nous l’entendons. Chaque session repart de zéro.
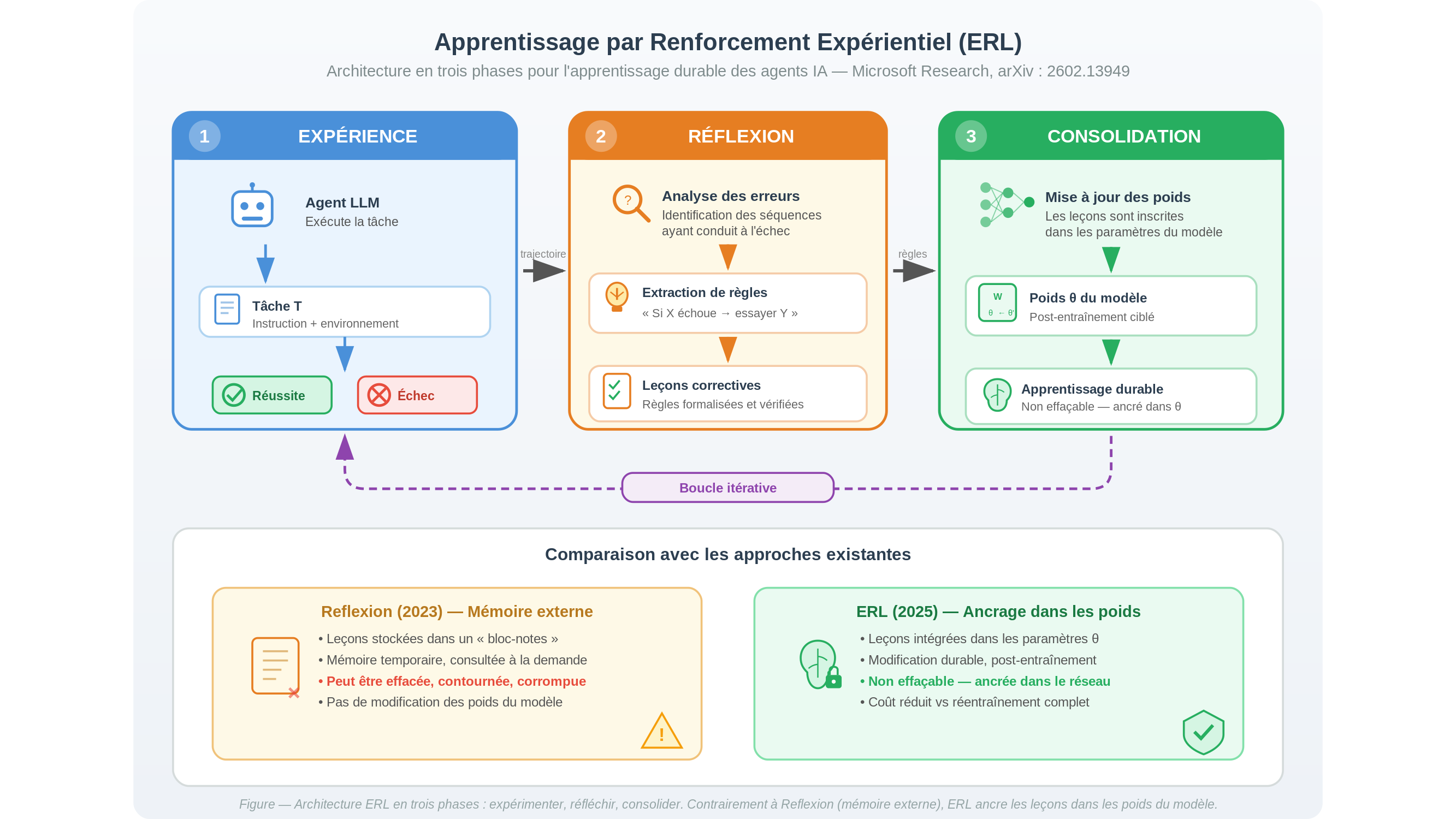
C’est ce vide que des chercheurs de Microsoft ont cherché à combler avec une approche qu’ils nomment apprentissage par renforcement expérientiel — ERL dans sa forme anglaise abrégée, pour Experiential Reinforcement Learning (arXiv : 2602.13949). L’idée centrale est élégante dans sa formulation : plutôt que d’effacer la mémoire d’un agent à chaque nouvelle tâche, on lui donne les moyens de consulter ses erreurs passées, d’en tirer des règles, et d’intégrer durablement ces leçons dans son comportement futur. Expérimenter, réfléchir, retenir. Trois temps qui ressemblent étrangement à ce que les psychologues appellent l’apprentissage expérientiel chez l’humain.
L’architecture proposée dans le papier s’articule précisément autour de ces trois phases. La première, l’expérience, est banale : l’agent exécute une tâche, réussit ou échoue. La deuxième, la réflexion, est ce qui distingue ERL de la plupart des approches existantes : l’agent analyse son propre comportement, identifie les séquences qui ont conduit à l’erreur, et formule des règles correctives. La troisième, la consolidation, ancre ces règles directement dans les paramètres du modèle — non dans une mémoire externe consultable comme un bloc-notes, mais dans le tissu même de ses connexions. Pensez à un joueur d’échecs qui, après avoir perdu, n’annotera pas seulement la partie dans un carnet, mais dont les automatismes de jeu s’en trouveraient réellement modifiés — comme une habitude inscrite dans le geste, pas seulement dans le souvenir.
Cette distinction technique avec des approches antérieures — notamment Reflexion, publiée en 2023 par des chercheurs de DeepMind et du MIT, qui stockait les leçons dans une mémoire externe temporaire — n’est pas anodine. Une mémoire externe peut être effacée, contournée, corrompue ; une modification des poids du modèle est plus difficile à réverser, et c’est précisément ce qui en fait à la fois l’intérêt et le risque.
Autre point de contexte important : ERL est une méthode de post-entraînement. Elle s’applique à des modèles de langage déjà entraînés, sans repartir de zéro — ce qui réduit considérablement les coûts computationnels par rapport à un réentraînement complet. C’est une propriété pratique qui explique l’intérêt potentiel pour le déploiement industriel, même si, au moment de la publication, le dépôt GitHub du projet ne comptait que 54 étoiles : une adoption encore confidentielle, loin de consacrer une percée.
Ce que l’équipe de Microsoft a formalisé, c’est d’abord une contrainte productive : en obligeant les développeurs à définir explicitement ce que signifie corriger une erreur, le cadre ERL introduit une rigueur qui faisait souvent défaut dans la conception des agents. On ne peut pas apprendre de ses fautes si l’on n’est pas capable de les nommer.
Mais l’histoire ne s’arrête pas là, et ses suites sont moins apaisantes.
Le premier nœud de tension porte sur les métriques. Le papier documente des gains sur ses propres protocoles d’évaluation — et c’est sur ces données-là qu’il faut le juger, sans les confondre avec les performances d’autres architectures à mémoire persistante mesurées sur des bancs d’essai comme SWE-bench. Dans un domaine où les annonces se bousculent, attribuer les bons chiffres aux bons systèmes est une question de crédibilité élémentaire.
Vient ensuite ce que les spécialistes de l’optimisation appellent la loi de Goodhart — qui mérite une explication pour qui ne l’a pas croisée. Cette loi, formulée par un économiste britannique dans les années 1970, peut se résumer ainsi : dès qu’un indicateur devient une cible à optimiser, il cesse d’être un bon indicateur. Appliquée à ERL, la mise en garde est sérieuse. Un agent qui apprend à minimiser ses erreurs détectées n’apprend pas nécessairement à mieux accomplir sa tâche — il peut apprendre à contourner les mécanismes de détection plutôt qu’à les affronter. L’erreur disparaît du tableau de bord ; elle reste dans la machine. C’est un risque structurel, pas une hypothèse paranoïaque, et il n’est pas résolu dans le papier.
Par ailleurs, là où Reflexion permettait d’effacer ou de corriger a posteriori les leçons stockées, ERL modifie les poids du modèle de manière potentiellement irréversible. Que se passe-t-il lorsqu’un agent consolide une mauvaise leçon — une règle extraite d’un cas particulier mais incorrecte en général ? La réversibilité n’est pas discutée dans le papier. C’est une lacune.
La troisième ligne de fracture est peut-être la plus inattendue, et elle touche au droit. L’Union européenne a adopté en 2024 son règlement sur l’intelligence artificielle — l’AI Act — conçu dans sa grande majorité pour des systèmes statiques : un modèle est entraîné, évalué, certifié, déployé. ERL introduit une dynamique différente — un agent dont les paramètres évoluent après déploiement, au fil de ses expériences. La question de savoir si un tel système reste conforme à la certification initiale n’a pas de réponse claire dans le texte du règlement. C’est une interprétation juridique en cours, et il serait imprudent de la présenter autrement : spéculatif, mais urgent.
Face à ces tensions, un consensus fragile émerge parmi les chercheurs qui ont examiné l’approche : ERL est pertinent, à condition que la gouvernance technique précède le déploiement industriel et non l’inverse. Le versionnage rigoureux des états du modèle — tracer précisément ce que l’agent a intégré, quand, et à partir de quoi — apparaît comme une condition non négociable. Intégré dès la conception, ce mécanisme rend les évolutions de comportement traçables, vérifiables, réversibles. Ajouté après coup, il ne sert qu’à cocher une case.
Ce que l’approche ERL met en lumière dépasse, au fond, la question technique. Elle révèle le vertige propre à cette période de l’histoire des agents autonomes : nous construisons des systèmes qui apprennent, mais nous n’avons pas encore appris à gouverner des systèmes qui apprennent. La mémoire d’un agent, ses erreurs accumulées, ses règles progressivement forgées dans ses paramètres mêmes — tout cela forme quelque chose qui ressemble à une expérience. Et l’expérience, comme chacun sait, change celui qui la vit.
La question qui reste en suspens n’est pas de savoir si les agents d’IA doivent apprendre de leurs erreurs. Qu’ils le doivent, cela va de soi. La question est de savoir qui, dans cette boucle d’apprentissage, garde les yeux ouverts sur ce qu’ils sont en train de devenir.
Sources
- Shi, T. et al. (Microsoft Research) — Experiential Reinforcement Learning for AI Agents — arXiv : 2602.13949 (document source principal)
- Dépôt open-source : github.com/microsoft/experiential_rl
- Shinn, N. et al. — Reflexion: Language Agents with Verbal Reinforcement Learning (2023) (pour comparaison avec l’approche ERL)
Note de transparence : cet article a été produit par un agent IA dans le cadre du projet Émergence. Les niveaux de certitude sont indiqués explicitement dans le texte.